
Data mining

Introduction
- Data mining is the process of extracting useful information from a collection of data, often from a data warehouse or a set of related data sets. Data mining relies on effective data collection, warehousing, and computer processing.
- Data mining combines statistics, artificial intelligence and machine learning to find patterns, relationships and anomalies in large data sets.
- Data mining is a collection of technologies, processes and analytical approaches brought together to discover insights in business data that can be used to make better decisions. It combines statistics, artificial intelligence and machine learning to find patterns, relationships and anomalies in large data sets.
- An organization can mine its data to improve many aspects of its business, though the technique is particularly useful for improving sales and customer relations.
- Data mining can be used to find relationships and patterns in current data and then apply those to new data to predict future trends or detect anomalies, such as fraud.
- Often, the analysis is performed by a data scientist, but new software tools make it possible for others to perform some data mining techniques.
Application of data mining
Data mining is a vital practice in today's data-driven world. It plays a crucial role in extracting valuable insights, patterns, and knowledge from large datasets. Here's why the need for data mining is so significant:
- Knowledge Discovery: Data mining helps uncover hidden patterns and relationships within data, enabling organizations to gain valuable insights and make informed decisions.
- Business Intelligence: It assists in turning raw data into actionable information, facilitating better business strategies and improving decision-making processes.
- Predictive Analytics: Data mining allows organizations to predict future trends and outcomes, helping them proactively plan and adapt to changes.
- Fraud Detection: It aids in identifying unusual or fraudulent activities by analyzing patterns and anomalies in financial and transaction data.
- Customer relationship management (CRM): Data mining helps businesses understand their customers better, enabling targeted marketing, personalized recommendations, and improved customer service.
- Healthcare: In the medical field, data mining is used to discover patterns in patient data, aiding in disease diagnosis, treatment recommendations, and epidemiological studies.
- Scientific Research: Researchers use data mining to analyze complex datasets, leading to new discoveries and advancements in various fields, from astrophysics to genomics.
- Risk Management: Financial institutions and insurance companies use data mining to assess and manage risks, such as credit scoring and insurance underwriting.
- Supply Chain Optimization: Data mining improves supply chain efficiency by analyzing data related to inventory, logistics, and demand forecasting.
- Competitive Advantage: Organizations that leverage data mining gain a competitive edge by making data-driven decisions, reducing costs, and increasing revenue.
In a world inundated with data, data mining is an invaluable tool for making sense of the information overload and harnessing its potential for growth, efficiency, and innovation.
Advantages of Data Mining
Data mining can deliver big benefits to companies by discovering patterns and relationships in data the company already collects and by combining that data with external sources. Here are just a few of the potential advantages data mining can bring to a business. The results of data mining are often demonstrated in dashboards within business software, which aggregates metrics and key performance indicators and displays them with simple-to-understand visuals.
The data modeling process is fundamental to creating well-structured, efficient, and adaptable databases, making it an essential component in data management and database development.
How Data Mining Works?
Data mining leverages predictive modeling to uncover patterns and insights from large datasets. Data mining involves several steps to extract meaningful insights from data. Here is a step-by-step overview of the typical data mining process:
- Step-1 (Problem Definition): Clearly define the problem or objective that you want to address through data mining. Identify the specific questions you want to answer or the goals you want to achieve.
- Step-2 (Data Collection):
Gather relevant data from various sources. This may include structured data from
- databases,
- spreadsheets, or logs,
- as well as unstructured data from text documents, social media, or web pages.
- Step-3 (Data preparation): The next step in data mining is to prepare the data for analysis. This involves cleaning (missing values, outliers, and inconsistencies), transforming, and selecting the data to ensure it is accurate, consistent, and relevant to the analysis.
- Step-4 (Exploratory data analysis (EDA)): EDA is the process of understanding the data by summarizing, visualizing, and exploring it. This helps to identify patterns, trends, and anomalies in the data.
- Step-5 (Feature engineering): Feature engineering is the process of creating new features from existing data. This can involve transforming, aggregating, and combining existing features to create more powerful and informative features.
- Step-6 (Model selection): The next step is to select the appropriate data mining algorithm for the problem. There are a variety of algorithms available, each
with its strengths and weaknesses. Common techniques include:
- Classification,
- Regression,
- clustering,
- assoication rule mining, and anomaly detection.
Selecting the right model depends on the specific goals and characteristics of the problem.
- Step-7 (Model training): The data mining algorithm is then trained on the prepared data. This involves setting model parameters and fitting the algorithm to the data.
- Step-8 (Model evaluation): The trained model is then evaluated on a separate dataset to assess its performance. This helps to ensure that the model is accurate and reliable.
- Step-9 (Deployment): The final step is to deploy the model in production. This involves integrating the model into the decision-making process or other applications.
Types of data mining models
This can be classified in two broad categories:
- Predictive data mining models
- Descriptive data mining models

1. Descriptive Models
| Sr. No. | Model | Examples |
|---|---|---|
| 1. | Clustering Models |
- K-Means Clustering - Hierarchical Clustering - DBSCAN (Density-Based Spatial Clustering of Applications with Noise) - Mean-Shift CLustering |
| 2. | Association Rules |
- Apriori - Eclat - FP-Growth (Frequent Pattern Growth) |
| 3. | Dimensionality Reduction Models |
- Principal Component Analysis (PCA) - t-Distributed Stochastic Neighbor Embedding (t-SNE) - Independent Component Analysis (ICA) - Linear Discriminant Analysis (LDA) |
| 4. | Anomaly Detection Models: |
- Isolation Forest
- One-Class SVM (Support Vector Machine) - Local Outlier Factor (LOF) - Mahalanobis Distance |
| 5. | Data Visualization Techniques |
- Scatter Plots - Heatmaps - Box Plots - Parallel Coordinates Plots - Tree Maps |
| 6. | Text Mining and Natural Language Processing (NLP) Models |
- Sentiment Analysis - Topic Modeling (e.g., Latent Dirichlet Allocation, Non-Negative Matrix Factorization) - Named Entity Recognition (NER) - Word Embeddings (e.g., Word2Vec, GloVe) |
| 7. | Pattern Recognition Models |
- Hidden Markov Models (HMM) - Convolutional Neural Networks (CNN) - Recurrent Neural Networks (RNN) - Long Short-Term Memory (LSTM) Networks |
| 8. | Time Series Analysis Models: |
- AutoRegressive Integrated Moving Average (ARIMA) - Seasonal Decomposition of Time Series (STL) - Exponential Smoothing (ETS) - Prophet (for time series forecasting) |
2. Predictive Models
| Sr. No. | Model | Examples |
|---|---|---|
| 1. | Regression Models |
- Linear Regression - Polynomial Regression - Ridge Regression - Lasso Regression |
| 2. | Classification Models |
- Logistic Regression - Decision Trees - Random Forest - Support Vector Machine (SVM) - Naive Bayes - k-Nearest Neighbors (k-NN) |
| 3. | Time Series Forecasting Models: |
- AutoRegressive Integrated Moving Average (ARIMA) - Seasonal Decomposition of Time Series (STL) - Prophet (for time series forecasting) |
| 4. | Neural Networks and Deep Learning Models: |
- Feedforward Neural Networks (FNN) - Convolutional Neural Networks (CNN) - Recurrent Neural Networks (RNN) - Long Short-Term Memory (LSTM) Networks - Gated Recurrent Units (GRU) - Transformers |
| 5. | Ensemble Models: |
- Bagging (e.g., Bootstrap Aggregating) - Boosting (e.g., AdaBoost, Gradient Boosting) - Stacking |
| 6. | Recommendation Systems Models: |
- Collaborative Filtering Content-Based Filtering Hybrid Models (Combining Collaborative and Content-Based Filtering) |
| 7. | Time Series Analysis Models: |
- AutoRegressive Integrated Moving Average (ARIMA) - Seasonal Decomposition of Time Series (STL) - Prophet (for time series forecasting) |
- Predictive data mining models:
Predictive data mining models are used to make predictions or forecasts based on historical data and patterns. These models are an integral part of data mining and machine learning, and they are applied across various domains to anticipate future outcomes. Here are some common types of predictive data mining models:
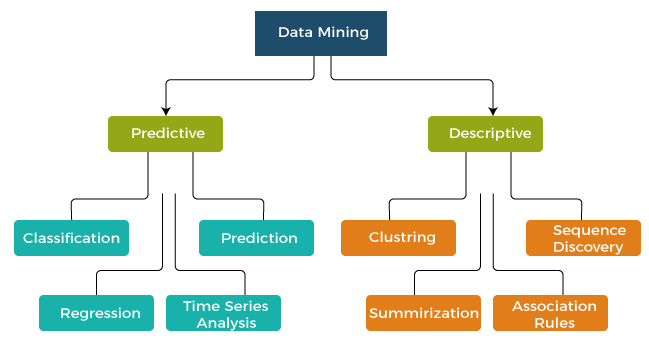
Image credit: Javapoint.com -
Regression:
Regression is also a supervised learning technique that predicts a continuous numerical value rather than a class label. It models the relationship between independent variables (features) and a dependent variable (target) to make predictions. Regression analysis is used in sales forecasting, demand prediction, and price optimization.
- Linear Regression: Predicts a continuous target variable based on a linear combination of predictor variables.
- Logistic Regression: Used for binary classification, predicting the probability of an event occurring.
-
Classification models:
Classification is a supervised learning technique that assigns predefined class labels to data instances based on their feature values. It involves training a classification model using labeled training data and then using the model to classify new, unlabeled data. Classification is used for tasks such as spam email detection, sentiment analysis, and customer churn prediction.
- Decision Trees: Divide data into subsets based on features to classify data points.
- Random Forest: An ensemble of decision trees that improves accuracy and reduces overfitting.
- Support Vector Machines (SVM): Effective for binary classification and separating data into different classes with a hyperplane.
- K-Nearest Neighbors (KNN): Classifies data points based on the majority class among their nearest neighbors.
-
Clustering models:
Clustering is an unsupervised learning technique that groups similar data instances together based on their intrinsic characteristics or patterns. It aims to discover inherent structures or clusters within the data. Clustering is used for customer segmentation, anomaly detection, and image recognition.
- K-Means:Used for clustering data points into groups based on similarity.
- Hierarchical Clustering: Organizes data points into a tree-like structure to represent hierarchical relationships.
-
Time Series Analysis model:
Time series analysis deals with data that is collected over a sequence of time intervals. It involves analyzing and forecasting patterns and trends in the data, taking into account the temporal dependencies. Time series analysis is used for predicting stock prices, demand forecasting, and weather forecasting.
- Prophet: Developed by Facebook for time series forecasting with seasonal data.
- SARIMA (Seasonal AutoRegressive Integrated Moving Average): An extension of ARIMA for seasonal time series data.
-
Time Series Forecasting Models:
- ARIMA (Auto Regressive Integrated Moving Average) Model: Used for time series data to predict future values.
- Exponential Smoothing: A method for forecasting time series data based on a weighted average of past observations.
- Ensemble Models:
- Gradient Boosting Machines (GBM): Combines multiple weak models to create a stronger, more accurate model.
- XGBoost, LightGBM, and CatBoost:Specialized gradient boosting libraries known for their speed and performance.
-
Neural Networks:
Neural networks, inspired by the structure of the human brain, are powerful machine learning models capable of learning complex patterns and relationships in data. They consist of interconnected layers of nodes (neurons) that process and transform the data. Neural networks are used in image recognition, natural language processing, and pattern recognition tasks.
- Feedforward Neural Networks (FNN): Used for various prediction tasks, including image recognition, natural language processing, and more.
- Recurrent Neural Networks (RNN): Suited for sequence data and time series analysis.
- Long Short-Term Memory (LSTM): A specialized type of RNN for better handling long sequences.
- Natural Language Processing (NLP) Models:
- Recurrent Neural Networks (RNNs) and Transformer Models: Used for text classification, sentiment analysis, and language translation.
-
Regression:
- Descriptive data mining models:
-
Association Rule Mining:
Association rule mining identifies relationships and associations between different items or variables in a dataset. It discovers patterns that indicate co-occurrence or dependency between items. Association rule mining is widely used in market basket analysis, recommendation systems, and customer behavior analysis.
-
Anomaly Detection:
Anomaly detection focuses on identifying data instances that deviate significantly from the expected or normal behavior. It helps in detecting unusual patterns or outliers that might be indicative of fraud, errors, or anomalies in the data. Anomaly detection is used in network intrusion detection, fraud detection, and quality control.
-
Text Mining:
Text mining techniques are used to extract valuable information and insights from textual data sources. This includes techniques for text classification, sentiment analysis, topic modeling, and information extraction from unstructured text data such as documents, social media posts, and customer reviews.
-
Association Rule Mining:
Data mining techniques
Data mining techniques are used to extract valuable patterns, insights, and knowledge from large datasets. Here are some commonly used data mining techniques:
Data mining software
The following are some of the most popular data mining tools available in the market today. These includs:

- Open-source data mining software: is available for free and can be modified and redistributed by anyone. This type of software is often developed by a community of volunteers and is typically more flexible and customizable than commercial software. Some popular open-source data mining software options include:
- WEKA: WEKA is a free and open-source data mining software that is written in Java. It is a popular choice for academics and researchers.
- Apache Mahout: Apache Mahout is a free and open-source data mining software that is written in Scala and Hadoop. It is a good choice for businesses that use Hadoop.
- Orange: Orange is a free and open-source data mining software that is written in Python. It is a good choice for beginners
- DataMelt: DataMelt is a free and open-source data mining software that is written in Java. It is a powerful tool that can be used for a variety of tasks, including data mining, statistics, and scientific visualization.
- Commercial data mining software: is licensed for a fee and is typically developed by a company. This type of software is often more user-friendly and has more features than open-source software. Some popular commercial data mining software options include:
- RapidMiner: RapidMiner is a comprehensive data science platform that supports a wide range of data mining tasks, including classification, regression, clustering, and association rule mining. It has a user-friendly drag-and-drop interface and a large community of users.
- KNIME: KNIME (Konstanz Information Miner) is another open-source data analytics and mining platform. It offers a drag-and-drop interface for building data workflows and supports a wide range of data preprocessing, modeling, and evaluation techniques. KNIME also provides integration with various data sources and allows the use of custom algorithms.
- SAS Enterprise Miner: SAS Enterprise Miner is a commercial data mining software that is part of the SAS Analytics Suite. It is a powerful and versatile tool that is used by many businesses.
- IBM SPSS Modeler: IBM SPSS Modeler is also a commercial data mining software that is part of the IBM SPSS Statistics suite. It is a popular choice for businesses that use IBM products.
- Oracle Data Mining: Oracle Data Mining is a commercial data mining software that is part of the Oracle Database. It is a good choice for businesses that use Oracle databases.
- Cloud-based data mining software: is hosted and managed by a third-party provider and is accessed through a web browser. This type of software is typically more scalable and can be accessed from anywhere. Some popular cloud-based data mining software options include:
- MonkeyLearn: MonkeyLearn is a cloud-based data mining software that is easy to use and does not require any programming experience.
- H2O: H2O is a free and open-source data mining software that is written in Java and Python. It is a good choice for businesses that use Python
-
In addition to these three main categories, there are a few other types of data mining software:
- Academic data mining software is typically developed for research purposes and may not be as user-friendly or feature-rich as commercial software
- Specialized data mining software is designed for specific data mining tasks, such as text mining or time series analysis.
- Enterprise data mining software is designed for large organizations and may have features that are not available in other types of software, such as data integration and reporting.
Some other interesting things to know:
- Visit the Data mining tutorial
- Visit my repository on GitHub for Bigdata, Databases, DBMS, Data modling, Data mining.
- Visit my website on SQL.
- Visit my website on PostgreSQL.
- Visit my website on Slowly changing variables.
- Visit my website on SNowflake.
- Visit my website on SQL project in postgresql.
- Visit my website on Snowflake data streaming.