
Snowflake: The Data Cloud for Businesses of All Sizes
Introduction
Snowflake is a fully-managed, petabyte-scale cloud data warehouse that enables businesses of all sizes to store, share, and analyze data in a secure and scalable way. Snowflake's unique architecture separates storage and compute, which allows for unprecedented performance and scalability. It also offers a variety of features that make it easy to get started with and manage, including:
- Elastic scalability: Snowflake can automatically scale up or down to meet the needs of your workload, so you only pay for what you use.
- Performance: Snowflake is designed to deliver high performance for even the most demanding workloads. It can query petabytes of data in seconds.
- Security: Snowflake offers a variety of security features to protect your data, including row-level security, column-level security, and encryption.
- Ease of use: Snowflake is easy to get started with and manage, even for users with no prior experience with data warehouses.
Snowflake is used by a wide variety of businesses, from startups to Fortune 500 companies. It is a popular choice for data warehousing, analytics, and machine learning applications.
Benefits of using Snowflake
Snowflake offers a number of benefits over traditional on-premises data warehouses, including:
- Cost savings: Snowflake's pay-as-you-go pricing model can save businesses significant amounts of money on hardware, software, and maintenance costs.
- Scalability: Snowflake can scale to meet the needs of even the most demanding workloads. It can easily handle petabytes of data and thousands of concurrent users.
- Performance: Snowflake is designed to deliver high performance for even the most complex queries.
- Security: Snowflake offers a variety of security features to protect your data, including row-level security, column-level security, and encryption.
- Ease of use: Snowflake is easy to get started with and manage, even for users with no prior experience with data warehouses.
Use cases for Snowflake
Snowflake is a versatile data platform that can be used for a variety of purposes, including:
- Data warehousing: Snowflake can be used to store, share, and analyze all types of data, from structured to unstructured.
- Analytics: Snowflake can be used to perform complex analytics on your data, such as machine learning, artificial intelligence, and natural language processing.
- Business intelligence: Snowflake can be used to create dashboards and reports that provide insights into your business performance.
- Data science: Snowflake can be used to build and deploy data science models.
- Application development: Snowflake can be used as a data store for your applications.
Prerequisites
Snowflake objects are the basic building blocks of the Snowflake data platform. They are used to organize and manage data, and to perform various data operations. Snowflake objects are organized into a hierarchy, with the following levels:
- Account: A Snowflake account is the top level of the hierarchy. It is a unique identifier for your Snowflake organization.
- Database: A database is a collection of Snowflake objects, such as tables, views, and functions.
- Schema: A schema is a logical grouping of Snowflake objects within a database.
- Object: A Snowflake object is a logical entity that stores or manipulates data.
The following are the different types of Snowflake objects:
- Tables: Tables are the primary data structures in Snowflake. They are used to store structured data in rows and columns.
- Views: Views are virtual tables that are derived from one or more base tables. They can be used to simplify complex queries or to restrict access to certain data.
- Schema: a schema is a logical grouping of database objects within a database. Schemas can be used to organize objects by subject area or department. For example, a company might have a schema for sales data, a schema for customer data, and a schema for employee data.
- Functions: Functions are user-defined procedures that can be used to perform complex calculations or transformations on data.
- Warehouses: Warehouses are compute resources that are used to process Snowflake queries. They are available in different sizes and performance levels.
- Streams: Streams are used to ingest and process real-time data in Snowflake.
- Stages: Stages are used to temporarily store data before it is loaded into Snowflake tables.
- File formats: File formats are used to define how data is stored in Snowflake files.
Getting started with Snowflake
- Access Snowflake: Log in to your Snowflake account.
- Create a Database: If you don't have one already, create a database to store your data.
- Data Loading:
- Load your data into Snowflake using methods like SnowSQL, Snowpipe, or Snowflake's web interface.
- Ensure your data is properly formatted and structured.
- Schema Design: Define the schema for your data, specifying tables, columns, and data types.
- Data Exploration:
- Use SQL queries to explore your data.
- Leverage Snowflake's support for SQL to perform data analysis.
- Data Transformation: Utilize SQL queries to clean and transform your data as needed.
- Data Visualization:
- Connect Snowflake to your preferred data visualization tool, like Tableau or Power BI.
- Create meaningful visualizations to interpret and present your data.
- Performance Optimization: Optimize your queries for performance by using features like materialized views and clustering keys.
- Data Security: Implement proper security measures to protect your data, including role-based access control.
- Scaling: Snowflake offers the ability to scale your data warehousing needs as required. Adjust resources when needed.
- Monitoring and Management:
- Regularly monitor query performance and system health.
- Use Snowflake's features for system management and maintenance.
- Documentation: Keep records of your queries and analysis for future reference and collaboration.
- Collaboration: Share insights and findings with your team or stakeholders as necessary.
Connect to Snowflake
Snowflake provides several different methods to interact with the Snowflake database including Snowsight, SnowSQL and the Snowflake Classic Console.
- Snowflake Ecosystem: SnowSQL (command line interface), connectors for Python and Spark, and drivers for Node.js, JDBC, ODBC, and more.
- Snowsight: Snowflake Web Interface
- SnowSQL (CLI Client)
- Classic Console
- Snowflake Extension for Visual Studio Code
- Snowflake Ecosystem:
- SnowSQL (Command Line Interface): SnowSQL is a command-line client provided by Snowflake, allowing you to manage your Snowflake account, execute SQL queries, and perform administrative tasks. It's a versatile tool for command-line interactions.
- Connectors for Python and Spark: Snowflake offers connectors for python and Spark, enabling seamless integration of Snowflake into data analysis workflows. They provide an interface for connecting, querying, and data transfer.
- Drivers for Node.js, JDBC, ODBC, and More: Snowflake provides drivers for multiple programming languages, facilitating connections from various applications.
- Snowsight (Snowflake Web Interface): Snowsight is a web-based user interface for Snowflake, offering an easy way to interact with Snowflake directly in your web browser.
- Classic Console: The Classic Console provides a web-based interface similar to Snowsight, and it's accessible for users who prefer it.
- Snowflake Extension for Visual Studio Code: This extension enhances your Snowflake development experience in Visual Studio Code with features like SQL code highlighting and autocompletion.
Creating a Snowflake Warehouse and Users
- Standard
- Snowpark-optimized
- Log in to Snowflake: Log in to your Snowflake account through the web interface or SnowSQL.
- Access the Snowflake Web Interface: If you're using the web interface, click on the "Warehouses" tab.
- Create a Warehouse :
A warehouse can be created through the web interface or using SQL:
- Classic Console:
Select Warehouses » Create
- Snowsight: Using Snowflake Web Interface:
Select Admin » Warehouses » Warehouse
- Click the "Create" button in the "Warehouses" tab.
- Fill out the warehouse details, including the name, size, and auto-pause settings.
- Click "Create Warehouse."
- Using SnowSQL:
Execute a CREATE WAREHOUSE command
CREATE WAREHOUSEWAREHOUSE_TYPE = { STANDARD | SNOWPARK-OPTIMIZED } WAREHOUSE_SIZE = { XSMALL | SMALL | MEDIUM | LARGE | XLARGE | XXLARGE | XXXLARGE | X4LARGE | X5LARGE | X6LARGE } MAX_CLUSTER_COUNT = {1 to 10} MIN_CLUSTER_COUNT = {1 to 10} SCALING_POLICY = { STANDARD | ECONOMY } AUTO_SUSPEND = { Any integer 0 or greater, | NULL } AUTO_RESUME = { TRUE | FALSE } -- TRUE(Default): The warehouse resumes when a new query is submitted. INITIALLY_SUSPENDED = { TRUE | FALSE }; -- FALSE(Default): The warehouse starts running after it is created. -- For example:
CREATE WAREHOUSE my_warehouse WAREHOUSE_SIZE = 'X-SMALL' AUTO_SUSPEND = 1800 AUTO_RESUME = TRUE;here, you can find the different sizes available in snowflake by object 'WAREHOUSE_SIZE': go to warehouse configuration page.
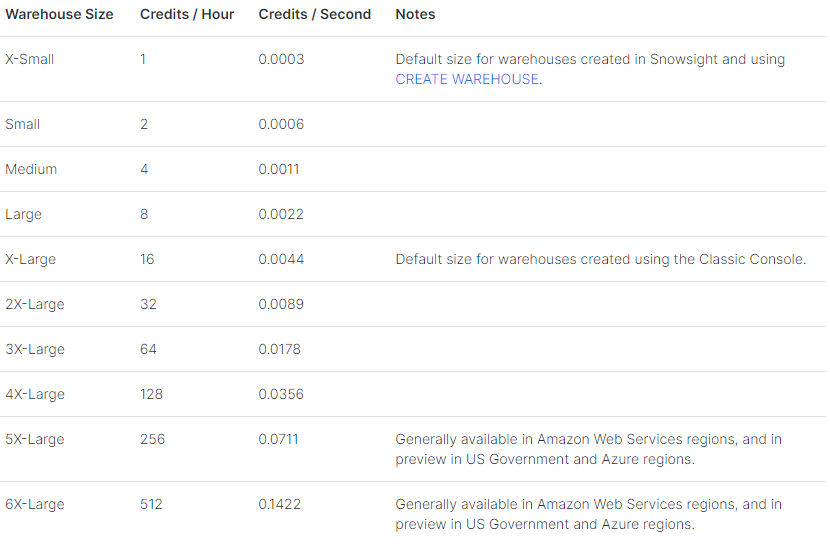
- Classic Console:
- Access the Snowflake Web Interface: Click on the "Users and Roles" tab.
- Create a Role:
- Click on the "Roles" tab and then the "Create" button.
- Provide a name and description for the role.
- Configure the role's privileges and access.
- Create a User:
- Click on the "Users" tab and then the "Create" button.
- Provide a username, password, and other user details.
- Assign the user to the role you created.
User can also be created using user management:
CREATE USER 'username' --Required Parameters -- PASSWORD = 'user_password' --Optional -- LOGIN_NAME = 'name' --Optional -- DISPLAY_NAME = 'display name' --Optional -- FIRST_NAME = 'First name' --Optional -- MIDDLE_NAME = 'Middle name' --Optional -- LAST_NAME = 'Last name' --Optional -- EMAIL = 'give email id' --Optional -- MUST_CHANGE_PASSWORD = TRUE | FALSE; -- If True, specifies whether the user is forced to change their password on next login -- - Access the Snowflake Web Interface: Navigate to the "Users and Roles" tab.
- Edit User Privileges:
- Find the user you created and click on their name.
- Click the "Change Roles" button to assign the user to a role that has access to the warehouse you created.
- Access Control for Warehouse:
- Ensure that the role assigned to the user has the appropriate access control for the warehouse. You can manage these permissions in the role settings.
- Save Changes: Save your changes, and the user will have access to the warehouse.
Creating a Warehouse:
A virtual warehouse, often referred to simply as a “warehouse”, is a cluster of compute resources in Snowflake. A virtual warehouse is available in two types:
Creating Users for the Warehouse:
Assigning the Warehouse to a User:
Example: A example of creating a user as ACCOUNTADMIN, or a role, or granting a appropriate privileges:
-- Assign a Warehouse to a User
USE ROLE ACCOUNTADMIN; -- You may need the appropriate role privileges to perform this operation
-- Modify the User's Role to Include Warehouse Access
GRANT ROLE 'role_name' TO USER 'username';
-- Grant Appropriate Warehouse Privileges to the Role
GRANT USAGE ON WAREHOUSE 'warehouse_name' TO ROLE 'role_name';
-- Optionally, you can grant additional privileges if needed:
-- GRANT EXECUTE TASK ON WAREHOUSE 'warehouse_name' TO ROLE 'role_name';
-- GRANT MONITOR ON WAREHOUSE 'warehouse_name' TO ROLE 'role_name';
-- Make sure the user's session uses the assigned role (OPTIONAL)
ALTER USER 'username' SET DEFAULT_ROLE = 'role_name';
Loading data into snowflake
Semi-structured Data
- Data can come from many sources, including applications, sensors, and mobile devices. To support these diverse data sources, semi-structured data formats have become popular standards for transporting and storing data. Snowflake provides built-in support for importing data from (and exporting data to) the following semi-structured data formats:
- JSON
- Avro
- ORC
- Parquet
- XML
- JSON data structure: JSON (JavaScript Object Notation) is a lightweight data-interchange format that is easy for humans to read and write and easy for machines to parse and generate. It's a widely used data structure in various applications, including web services, configuration files, and data storage. JSON data is represented as a collection of key-value pairs, similar to Python dictionaries or JavaScript objects.
- Object: A JSON object is enclosed in curly braces '{}' and contains a collection of key-value pairs. Each key is a string, followed by a colon, and then the associated value.
- Array: A JSON array is enclosed in square brackets '[]' and contains an ordered list of values. Values can be strings, numbers, objects, arrays, booleans, null, or other valid JSON data types.
- String: A JSON string is a sequence of characters enclosed in double quotes. Strings are used for keys and values.
- Number: JSON numbers can be integers or floating-point numbers.
- Boolean: JSON has two boolean values: true and false.
- Null: The null value represents the absence of a value.
Snowflake provides native data types (ARRAY, OBJECT, and VARIANT) for storing semi-structured data.
{
"name": "John Doe",
"age": 30,
"isStudent": false,
"address": {
"street": "123 Main St",
"city": "Anytown",
"zipCode": "12345"
},
"hobbies": ["reading", "hiking", "painting"],
"contacts": [
{
"type": "email",
"value": "john.doe@email.com"
},
{
"type": "phone",
"value": "555-123-4567"
}
]
}
Snowflake is primarily designed for structured data, but it can handle semi-structured and unstructured data to some extent. When working with unstructured data in Snowflake, you typically use one of the following approaches:
- Using External Stages:
Snowflake allows you to use external stages to load data from cloud storage services like Amazon S3, Azure Blob Storage, or Google Cloud Storage. You can load unstructured data files (e.g., CSV, JSON, Parquet) into Snowflake tables, treating them as semi-structured data.
- Define an external stage pointing to your cloud storage location.
- Use the COPY INTO statement to load data from the external stage into a Snowflake table.
- You might need to use a VARIANT data type or a similar semi-structured data type to store unstructured content.
- Example (AWS):
-- Create a file format for JSON data (if not already created) CREATE OR REPLACE FILE FORMAT json_format TYPE = 'JSON'; -- Create an external stage CREATE OR REPLACE STAGE my_stage URL = 's3://your-bucket/path-to-data/' CREDENTIALS = (AWS_KEY_ID = 'your-key' AWS_SECRET_KEY = 'your-secret-key'); -- Copy JSON data into a Snowflake table COPY INTO my_table FROM @my_stage/file.json FILE_FORMAT = (TYPE = 'JSON'); - Azure Blob Storage External Stage:
-- Create a file format for JSON data (if not already created)
CREATE OR REPLACE FILE FORMAT json_format
TYPE = 'JSON';
CREATE OR REPLACE STAGE your_stage
URL = 'azure://your-container@your-storageaccount/path-to-data/'
CREDENTIALS = (
AZURE_SAS_TOKEN = 'your-sas-token'
);
-- Copy JSON data from the external stage to a Snowflake table
COPY INTO your_snowflake_table
FROM @your_stage/file.json
FILE_FORMAT = (TYPE = 'JSON');
-- Create a file format for JSON data (if not already created)
CREATE OR REPLACE FILE FORMAT json_format
TYPE = 'JSON';
CREATE OR REPLACE STAGE your_stage
URL = 'gcs://your-bucket/path-to-data/'
CREDENTIALS = (
GCS_JSON_KEY = 'your-json-key'
-- Copy JSON data from the external stage to a Snowflake table
COPY INTO your_snowflake_table
FROM @your_stage/file.json
FILE_FORMAT = (TYPE = 'JSON');
);
Replace the placeholders (your_stage, your-bucket, your-access-key, etc.) with your specific information.
- Create a table with a VARIANT or OBJECT column to store unstructured data
- Use the INSERT statement or other data manipulation techniques to populate the table with your unstructured data
- Here's an example:
-- Create a table with a VARIANT column
CREATE OR REPLACE TABLE my_table (
id NUMBER,
data VARIANT
);
-- Insert unstructured JSON data into the table
INSERT INTO my_table (id, data)
VALUES (1, PARSE_JSON('{"key": "value"}'));
- Preprocess Data: Use a scripting language (e.g., Python, JavaScript) or ETL tools to parse, structure, and transform the unstructured data into a structured format (e.g., CSV, JSON).
- Create a Snowflake Table: Define a structured Snowflake table that matches the format of the preprocessed data
- Load Structured Data: Use Snowflake's native loading methods, such as COPY INTO, to load the preprocessed structured data into the table
- Data Transformation: If additional data transformations are required, you can perform them using SQL in Snowflake.
The choice of method depends on your specific use case and data processing requirements. While Snowflake is capable of handling semi-structured data, sometimes external preprocessing may be necessary to ensure the data aligns with your needs before loading it into Snowflake.
Loading structured data
- AWS S3 Example:
-- Create a Snowflake table CREATE OR REPLACE TABLE your_table ( column1 STRING, column2 NUMBER, column3 DATE ); -- Define a file format for structured data (e.g., CSV) CREATE OR REPLACE FILE FORMAT your_file_format TYPE = 'CSV' SKIP_HEADER = 1; -- Skip the header row if present in your data -- Create an external stage for AWS S3 CREATE OR REPLACE STAGE your_s3_stage URL = 's3://your-bucket/path-to-data/' CREDENTIALS = ( AWS_ACCESS_KEY_ID = 'your-access-key', AWS_SECRET_ACCESS_KEY = 'your-secret-key' ); -- Copy structured data from the S3 stage into the Snowflake table COPY INTO your_table FROM @your_s3_stage/your-data-file.csv FILE_FORMAT = (FORMAT_NAME = your_file_format); - Azure Blob Storage Example:
-- Create a Snowflake table CREATE OR REPLACE TABLE your_table ( column1 STRING, column2 NUMBER, column3 DATE ); -- Define a file format for structured data (e.g., CSV) CREATE OR REPLACE FILE FORMAT your_file_format TYPE = 'CSV' SKIP_HEADER = 1; -- Skip the header row if present in your data -- Create an external stage for Azure Blob Storage CREATE OR REPLACE STAGE your_azure_stage URL = 'azure://your-container@your-storageaccount/path-to-data/' CREDENTIALS = ( AZURE_SAS_TOKEN = 'your-sas-token' ); -- Copy structured data from the Azure stage into the Snowflake table COPY INTO your_table FROM @your_azure_stage/your-data-file.csv FILE_FORMAT = (FORMAT_NAME = your_file_format); - Google Cloud Storage Example:
-- Create a Snowflake table CREATE OR REPLACE TABLE your_table ( column1 STRING, column2 NUMBER, column3 DATE ); -- Define a file format for structured data (e.g., CSV) CREATE OR REPLACE FILE FORMAT your_file_format TYPE = 'CSV' SKIP_HEADER = 1; -- Skip the header row if present in your data -- Create an external stage for Google Cloud Storage CREATE OR REPLACE STAGE your_gcs_stage URL = 'gcs://your-bucket/path-to-data/' CREDENTIALS = ( GCS_JSON_KEY = 'your-json-key' ); -- Copy structured data from the GCS stage into the Snowflake table COPY INTO your_table FROM @your_gcs_stage/your-data-file.csv FILE_FORMAT = (FORMAT_NAME = your_file_format);
It's important to note that while Snowflake can handle semi-structured and unstructured data to some extent, it may not be as efficient as specialized systems designed for unstructured data, like data lakes or NoSQL databases. Snowflake's strength lies in structured and semi-structured data processing.