Automated Real-Time Data Streaming Pipeline using Apache Nifi, AWS, Snowpipe, Stream & Task
"Unlocking the Power of Real-Time Data in the Cloud"
Introduction
In this project, I embarked on an exciting adventure in data engineering. I orchestrated the real-time flow of data using a fusion of modern technologies,
aiming to build a smart system. This system not only generates random data but also swiftly sends it to an AWS S3 storage space. Then, it processes this data
instantly with Snowflake, all under the watchful eye of Apache Nifi, which acts as the conductor of this intricate data symphony.
Prerequisites
Before diving into the project, you'll need the following prerequisites:
Project overview
This project demonstrates my ability to design and implement a real-time data streaming pipeline using Apache Nifi, AWS, Snowpipe,
Stream, and Task. The pipeline continuously ingests data from a JupyterLab notebook, processes it using Apache Nifi, and loads it into a Snowflake
data warehouse. The pipeline is designed to handle both new data and updates to existing data.
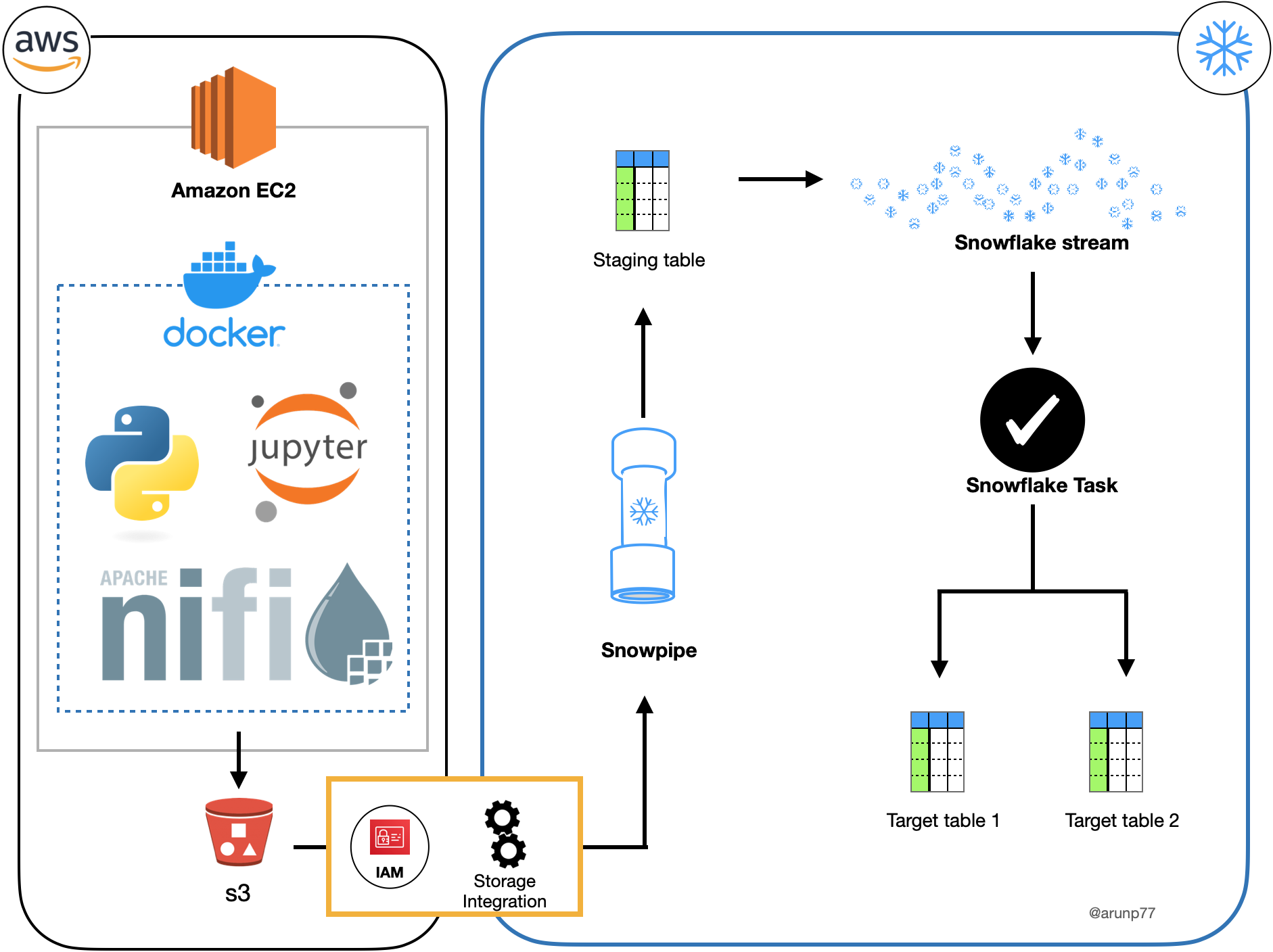
Project Architecture
The architecture of our project involves several interconnected components:
- EC2 Instance: This serves as the foundation of the project, where we deploy our Docker container and essential tools.
- Docker Container: Housed within the EC2 instance, this container contains Python, Apache Nifi, and Apache ZooKeeper, ensuring a consistent and easily replicable environment.
- JupyterLab and Apache Nifi: These are the workstations for data engineers. JupyterLab is accessible at 'IP/4888,' and Apache Nifi is reachable at 'IP/2080' (where IP is the
EC2 machine IP).
- Data Generation: Using Python in JupyterLab, we utilized the 'Faker' library to create random data records, including customer information.
- Data Streaming to AWS S3: Apache Nifi was used to establish connections for transferring the generated data to an AWS S3 bucket, providing scalable storage and real-time access.
- Real-Time Data Processing with Snowflake: Leveraging Snowpipe, we ensured that any new data or changes in existing data were automatically incorporated into the dataset. Slowly changing dimensions were used to track these changes.
- Target Table Creation: A task was executed to create target tables, ensuring the final dataset was always up-to-date and accurate.
Project Setup
Let's dive into the details of the setup, like taking a closer look at the instruments in our orchestra:
- EC2 Instance Configuration:
I carefully set up an AWS EC2 instance with 8GB of RAM, selecting a powerful t2.xlarge instance for the best performance on the Amazon Linux system.
We opened ports from 4000 to 38888 and established SSH access. Think of it as preparing a concert hall for our performance.
- Docker Container Setup: Within the EC2 instance, a Docker container was created and populated with Python,
Apache Nifi, and Apache ZooKeeper. Think of it as preparing our instruments, tuning them to perfection.
- JupyterLab and Apache Nifi Configuration: JupyterLab and Apache Nifi were configured to run on specific ports, making them accessible for data processing and orchestration.
It's like setting up the conductor's podium and the sheet music stand just right.
- Data Generation: In JupyterLab, Python code was crafted to generate random data, simulating customer information. This is where the composer writes the notes.
- Data Streaming: Apache Nifi was utilized to set up connections, ensuring the seamless transfer of generated data to an AWS S3 bucket. It's the conductor guiding the instruments.
- Real-Time Data Processing: Snowpipe, Snowflake streams, and tasks were set up to handle real-time data processing, enabling automatic updates as new data arrived.
It's the conductor guiding the orchestra to play in harmony.
- Slowly Changing Dimensions (SCD)
Implementation:
Within our orchestration, we employed the concept of Slowly Changing Dimensions (SCD) in Snowflake to maintain the integrity and history of our datasets.
Think of it as a conductor's keen ear for detecting subtle changes in the music.
- SCD-1 Method (Flagging Changes): With the SCD-1 approach, we tracked changes by flagging modified records. It's akin to marking specific musical
notes that need adjustment. As data evolved, we efficiently identified and marked the records that underwent changes, ensuring data accuracy.
- SCD-2 Method (Historical Versioning): In parallel, we implemented the SCD-2 method, creating a symphony of historical versions for our datasets.
Each change introduced a new version, preserving a complete history of our data, much like recording various performances of a musical composition.
We maintained records with attributes such as start dates, end dates, and version numbers, allowing us to trace the evolution of our datasets over time.
Key Components
The key components are like our orchestra members:
- AWS EC2: (The Stage Where the Symphony is Performed) The AWS EC2 instance serves as the stage for our data symphony. Here's how
it was created and configured for the project:
- Creation: To set up an EC2 instance, I began by accessing the AWS Management Console and launched an EC2 instance.
I selected an instance type with 8GB of RAM and 100GB of memory space, specifically choosing a t2.xlarge instance for optimal performance.
- Storage and Security: In the process, I configured the instance with 100GB of storage, ensuring that there was sufficient space to store data and project components. Additionally, I created a security group that allowed incoming traffic on the
specified ports and enabled SSH access for remote management.
- Connection: After launching the EC2 instance, I connected to it via SSH, providing a secure channel for executing commands and configuring the environment.
- Amazon S3 Terminology: Before we get started moving data, let’s establish some basic terminology:
- Identity and Access Management (IAM) – Controls for making and controlling who and what can interact with your AWS resources.
- Access Keys – These are your access credentials to use AWS. These are not your typical username/password — they are generated using access identity management.
- Bucket – A grouping of similar files that must have a unique name. These can be made publicly accessible and are often used to host static objects.
- Folder – Much like an operating system folder, these exist within a bucket to enable organization.
- Docker: ocker played a crucial role in maintaining the tools and dependencies used in the project. Here's how it was set up:
- Installation: To prepare the EC2 instance for Docker, I executed a series of commands:
sudo yum update -y
sudo yum install docker
Installing Docker Compose: I also installed Docker Compose to manage multi-container Docker applications.
This was achieved with the following commands:
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
Adding User to Docker Group: To ensure that I had the necessary permissions to interact with Docker without using sudo,
I added my user to the Docker group and activated the changes with:
sudo gpasswd -a $USER docker
newgrp docker
Python installation:I installed Python and the required package:
sudo yum install python-pip
Docker-compose: I've installed a customized Docker container that includes essential images for JupyterLab and Apache NiFi. A docker-compose
file is configuration file used with Docker compose, a tool that simplifies the management of multi-container Docker applications.
To start the continer:
docker-compose up
Jupyterlab
The JupyterLab can be access in browser:
http://[your-ec2-instance-ip]:4888/lab?
Apache Nifi: The Conductor
Apache Nifi was the conductor of our data symphony, orchestrating the flow of data. The apache-nifi can be access in browser:
http://[your-ec2-instance-ip]:2080/nifi?
Snowflake, snowpipe, snowflake stream and Task
- Snowpipe: Automates the process of ingesting data from your S3 bucket into Snowflake. It continuously loads data as it arrives, making it an
ideal solution for real-time data processing.
- Snowflake Stream: Captures changes to specific tables, including new data generated in JupyterLab and transferred to S3 by Apache NiFi. This stream ensures you're always working with the latest data.
- Snowflake Task: These tasks are configured to automatically execute SQL statements or stored procedures in response to changes in Snowflake Streams.
They enable real-time data processing and transformations, ensuring that new data is immediately available for analysis.
In my workflow, this combination of Snowflake, Snowpipe, Streams, and Tasks enables the seamless automation of data loading and processing as new data arrives,
eliminating manual intervention and ensuring up-to-the-minute data availability for your analytics and reporting needs.
The orchestration of these components is analogous to preparing an orchestra for a grand performance. The EC2 instance serves as the stage,
Docker maintains our instruments, and Apache Nifi conducts the symphony of data, guiding it through the intricacies of real-time processing and streaming.
Project Results
The project successfully achieved real-time data generation, streaming, and processing, showcasing the efficiency and scalability of the architecture.
It exemplified my proficiency in working with a diverse set of tools and technologies. Like any symphony, it was a harmonious blend of various elements,
each playing its role to create a beautiful performance.
Challenges Faced:
Although the project achieved great results, we encountered some hurdles. Think of it as fine-tuning a complex musical performance.
We had to make our data processing pipelines work faster for big datasets, ensure our real-time components were strong, and keep everything
moving smoothly. We tackled these challenges by carefully testing and making adjustments, just like a composer perfecting a symphony.
Future Improvements
To further enhance this project, future improvements may include:
- Implementing data quality checks for ensuring data accuracy.
- Integrating machine learning models for more sophisticated data analysis.
- Automating deployment and scaling of the architecture for handling larger and more extensive data streams, much like a symphony growing in scale and grandeur.
This project is a testament to my expertise in data engineering and real-time data processing.
It's more than just a project; it's a data symphony, where diverse tools and technologies come together to create a harmonious and ever-evolving performance.
