
Big Data

Big data
Big data refers to extremely large and complex datasets that cannot be easily managed, processed, or analyzed using traditional data processing techniques. It encompasses vast volumes of structured, semi-structured, and unstructured data that are generated at high velocity and variety.
The "Five Vs" of Big Data
Just because a data set is large does not necessarily mean it is big data. To qualify as big data, data must meet at least the following five characteristics:- Volume: While volume is far from the only reason big data is called "big," it is undoubtedly a key characteristic. To fully manage and leverage big data, advanced algorithms and AI-driven analytics are required. Before that can happen, however, there must be a secure and reliable means of storing, organizing, and retrieving the many terabytes of data that large enterprises accumulate.
- Velocity: In the past, all data generated had to be fed into a traditional database system, often manually, before it could be analyzed or retrieved. Big data technology today enables databases to process, analyze and configure data as it is being generated - sometimes in milliseconds. This enables companies to leverage real-time data to seize financial opportunities, respond to customer needs, prevent fraud and address any other activity where speed is critical.
- Variety: Datasets made up entirely of structured data aren't necessarily big data, no matter how large. Big data typically consists of combinations of structured, unstructured, and semi-structured data. Traditional databases and data management solutions lack the flexibility and functionality to manage the complex, disparate datasets that make up big data.
- Veracity: While modern database technology allows organizations to capture and make meaningful use of large amounts of data and diverse types of data, it is only valuable if it is accurate, relevant, and up-to-date. With traditional databases containing only structured data, syntactic errors and typos were the common culprits when it came to data accuracy. With unstructured data comes a whole new set of reliability challenges. Human bias, social noise, and questions about data lineage can impact data quality.
- Value: There is no question that the results of analyzing big data are often fascinating and unexpected. But for businesses, these analytics need to provide insights that help them become more competitive and resilient — and better serve their customers. Modern big data technologies enable data collection and retrieval that deliver measurable value for both business outcomes and operational resilience.

How big data works?
Big data is useful when the analysis provides relevant and actionable insights that measurably advance the business. With regard to the transformation of big data, companies should ensure that their systems and processes are sufficiently prepared for the collection, storage and analysis of this large amount of data.
The three most important steps in using Big Data:
- Capturing big data
- Store big data
- Analyzing big data

Big data analytics
Big Data Analytics involves analyzing vast volumes of structured, semi-structured, and unstructured data to uncover patterns, trends, and insights that can drive business decisions and strategies. It leverages advanced analytics techniques and technologies to process and interpret data from diverse sources.
Life cycle phases of big data analytics
The following are the phases in the life cycle of big data analytics in brief:
- Data Ingestion: This is the process of collecting, extracting, and loading data from various sources into a centralized data repository.
- Data Preparation: This is the cleaning, transforming, and preparing of data for analysis.
- Data Exploration and Modeling: This is the process of using various analytical techniques and tools to uncover patterns and insights in the data.
- Data Visualization and Reporting: This is the process of using visual aids to communicate the findings from the data analysis.
- Data Lifecycle Management: This is the process of managing the data throughout its lifecycle, from ingestion to visualization and reporting.
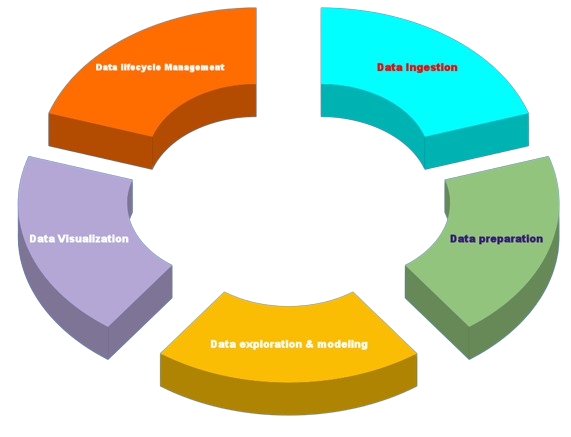
Big Data Analytics stages
Big Data Analytics involves several stages:
- Data Acquisition
- Data Storage
- Data processing
- Data analysis
- Visualization and reporting
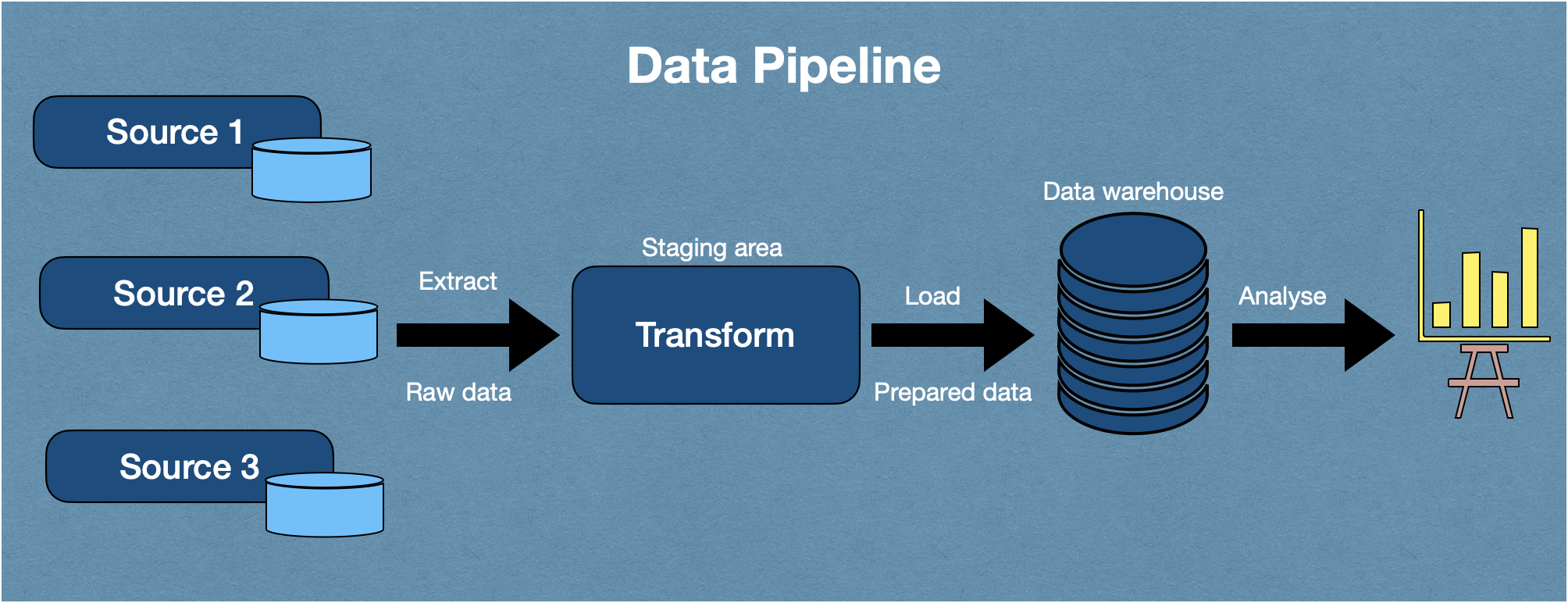
Benefits of Big Data Analytics:
Big data analytics and tools are used to help businesses improve their operations, decision-making processes, and overall performance. Here are some ways in which big data analytics and tools can contribute to business improvement:
- Improved Decision-making: Enables data-driven decision-making based on accurate insights and evidence.
- Enhanced Operational Efficiency: Identifies inefficiencies, optimizes processes, and reduces costs.
- Personalized Customer Experiences: Enables customization, targeted marketing, and better customer satisfaction.
- Predictive Capabilities: Provides insights for forecasting trends, identifying risks, and proactive decision-making
- Innovation and Discovery: Uncovers new patterns, opportunities, and potential innovations.
Challenges of Big Data Analytics:
- Data Volume and Variety: Handling and processing large and diverse datasets require scalable infrastructure and appropriate tools.
- Data Quality and Validity: Ensuring data accuracy, consistency, and relevancy can be challenging, especially with unstructured or incomplete data.
- Data Privacy and Security: Protecting sensitive data and complying with regulations to maintain privacy and security.
- Skills and Expertise: Acquiring and retaining skilled data professionals with expertise in big data analytics can be a challenge.
- Cost and Infrastructure: Establishing and maintaining the necessary infrastructure, tools, and technologies can be expensive.
How to Improve the Accuracy of Big Data Analysis?
Improving the accuracy of big data analysis is crucial for obtaining reliable and actionable insights. Here are some key steps you can take to enhance the accuracy of your big data analysis:
- Data Quality Assurance: Ensure that the data being analyzed is of high quality. Perform data cleaning, preprocessing, and validation to address issues such as missing values, outliers, inconsistencies, and data integrity problems. Validate the accuracy and reliability of data sources, and establish data governance practices to maintain data quality throughout the analysis process.
- Feature Selection and Engineering: Identify the most relevant features (variables) that have a strong impact on the analysis and remove irrelevant or redundant features. Feature engineering involves transforming or creating new features that can improve the accuracy of the analysis. This process requires domain expertise and an understanding of the specific problem being addressed.
- Proper Data Sampling: Sampling techniques can be used to select representative subsets of data for analysis, especially when dealing with large datasets. Ensure that the selected samples accurately represent the entire dataset and maintain the integrity of the analysis results. The choice of sampling method should be aligned with the objectives and characteristics of the data.
- Model Selection and Validation: Choose appropriate modeling techniques and algorithms that are well-suited for the specific analysis task. Validate the selected models using proper evaluation methods such as cross-validation, holdout validation, or bootstrap methods. Regularly review and refine the models to improve accuracy and address any overfitting or underfitting issues.
- Ensemble Methods: Employ ensemble methods that combine multiple models to improve accuracy. Ensemble techniques, such as bagging, boosting, and stacking, can help in reducing bias, variance, and error rates in the analysis. By leveraging the strengths of different models, ensemble methods can produce more accurate predictions or classifications.
- Continuous Monitoring and Iterative Refinement: Implement a feedback loop to continuously monitor the accuracy and performance of the analysis. Regularly evaluate the results against ground truth or real-world outcomes to identify any discrepancies or areas for improvement. Use the feedback to refine the analysis process, update models, and incorporate new data or insights.
- Domain Expertise and Contextual Understanding: Apply domain expertise and contextual understanding to interpret and validate the analysis results. Subject matter experts can provide valuable insights, validate the accuracy of the analysis, and ensure that the findings align with the business objectives and requirements.
- Collaborative Approach: Foster collaboration and communication between data analysts, data scientists, domain experts, and stakeholders. Encourage discussions, feedback, and validation from multiple perspectives to improve the accuracy of the analysis. Collaboration helps in identifying potential biases, validating assumptions, and gaining a holistic understanding of the data and its implications.
Some other interesting things to know:
- Visit the Data mining tutorial
- Visit my repository on GitHub for Bigdata, Databases, DBMS, Data modling, Data mining.
- Visit my website on SQL.
- Visit my website on PostgreSQL.
- Visit my website on Slowly changing variables.
- Visit my website on SNowflake.
- Visit my website on SQL project in postgresql.
- Visit my website on Snowflake data streaming.