
Hadoop: A Comprehensive Overview of Big Data Processing and Storage

Introduction to Hadoop
In a straightforward scenario with smaller data volumes, one might consider a system where users interact directly with standard database servers through a centralized system. However, in the case of large and scalable data, processing such data through a single database bottleneck becomes a challenging task. Hadoop is a framework written in Java that utilizes a large cluster of commodity hardware to maintain and store big size data. Hadoop works on MapReduce Programming Algorithm that was introduced by Google. This Algorithm divides the task into small parts and assign them to many computers, and collects the results from them which when integrated, from the result dataset.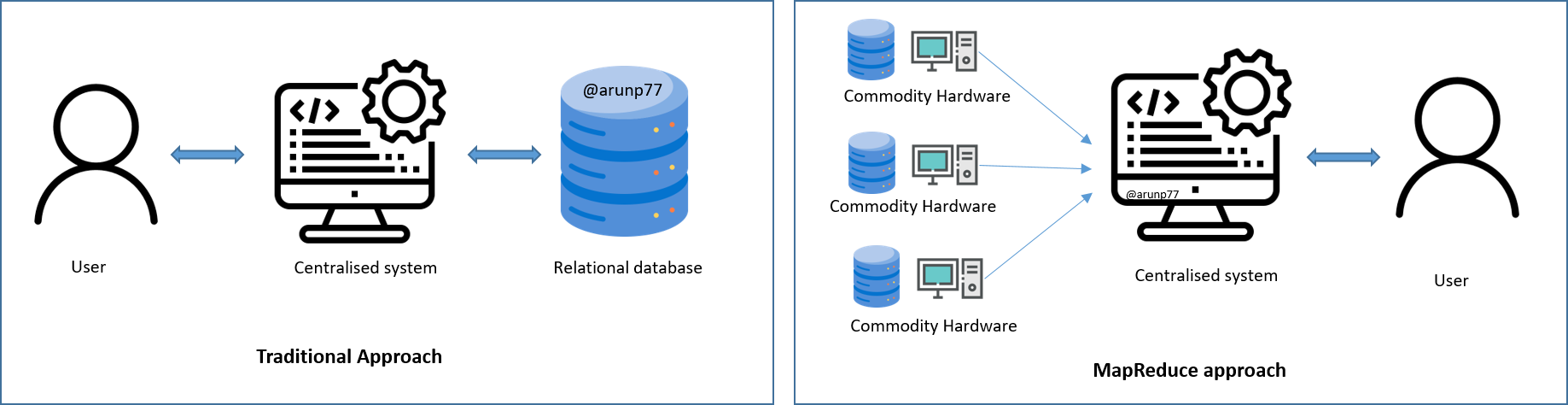
Definition: Hadoop, an Apache open-source framework written in Java, enables the distributed processing of large datasets across computer clusters using simple programming models. Operating in an environment with distributed storage and computation across clusters, Hadoop is designed to scale seamlessly from a single server to thousands of machines, each providing local computation and storage.
Example: For example, consider a dataset of 5 terabytes. If you distribute the processing across a Hadoop cluster of 10,000 servers, each server would need to process approximately 500 megabytes of data. This allows the entire dataset to be processed much faster than traditional sequential processing.
Hadoop has two major layers namely --
- Processing/Computation layer (MapReduce)
- Storage layer (Hadoop Distributed File System).
- MapReduce
- HDFS(Hadoop Distributed File System)
- YARN(Yet Another Resource Negotiator)
- Common Utilities or Hadoop Common
Advantegs of Hadoop
- Scalability: Hadoop is highly scalable, allowing for the easy addition of nodes to a cluster to handle increased data volume and processing requirements.
- Cost-Effective:Hadoop can store and process large volumes of data on commodity hardware, making it a cost-effective solution compared to traditional database systems.
- Parallel Processing: The MapReduce programming model enables parallel processing, distributing data across multiple nodes for faster and more efficient computation.
- Fault Tolerance: Hadoop is designed to be fault-tolerant. If a node fails, data can be easily recovered as it exists in multiple copies across the cluster.
- Flexibility: Hadoop can handle structured and unstructured data, making it suitable for a variety of data types, including text, images, and videos.
- Open Source: Hadoop is an open-source framework, which means it is accessible and customizable. The community support and continuous development contribute to its robustness.
- Ecosystem: The Hadoop ecosystem includes a variety of tools and frameworks (like Hive, Pig, Spark) that extend its functionality for different use cases, such as data warehousing, machine learning, and real-time processing.
Disadvantages of Hadoop
- Complexity: Implementing and managing a Hadoop cluster can be complex. It requires expertise in system administration, configuration, and tuning for optimal performance.
- Programming Model: Developing applications in the MapReduce programming model may be challenging for those unfamiliar with it. However, higher-level abstractions like Apache Spark have addressed some of these concerns.
- Real-time Processing: Hadoop's traditional batch processing model may not be suitable for real-time or low-latency processing requirements. Other tools like Apache Spark or Flink are better suited for these scenarios.
- Hardware Dependency: While Hadoop can run on commodity hardware, optimal performance often requires a dedicated cluster of powerful machines, which may increase infrastructure costs.
- Data Security: Hadoop's security features have evolved, but ensuring robust data security and access control can still be a concern, especially in large and complex deployments.
- Data Locality: While Hadoop aims for data locality (processing data on the node where it's stored), achieving perfect data locality is not always possible, impacting performance.
- Learning Curve: There is a learning curve associated with understanding and effectively using Hadoop and its associated tools, which may require additional training for teams unfamiliar with the ecosystem.
MapReduce
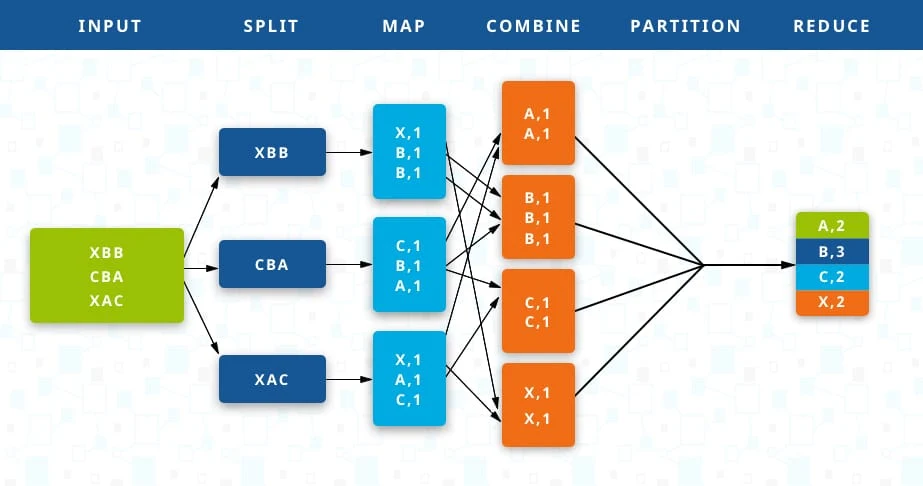
MapReduce is a parallel programming model for writing distributed applications devised at Google for efficient processing of large amounts of data (multi-terabyte data-sets), on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner. The significance of MapReduce is to facilitate concurrent data processing. To achieve this, massive volumes of data, often in the order of several petabytes, are divided into smaller chunks. These data chunks are processed in parallel on Hadoop servers. After processing, the data from multiple servers is aggregated to provide a consolidated result to the application. Hadoop is capable of executing MapReduce programs written in various languages, including Java, Ruby, Python, C++, etc. Data access and storage are disk-based. The inputs are stored as files containing structured, semi-structured, or unstructured data. The output is also stored as files.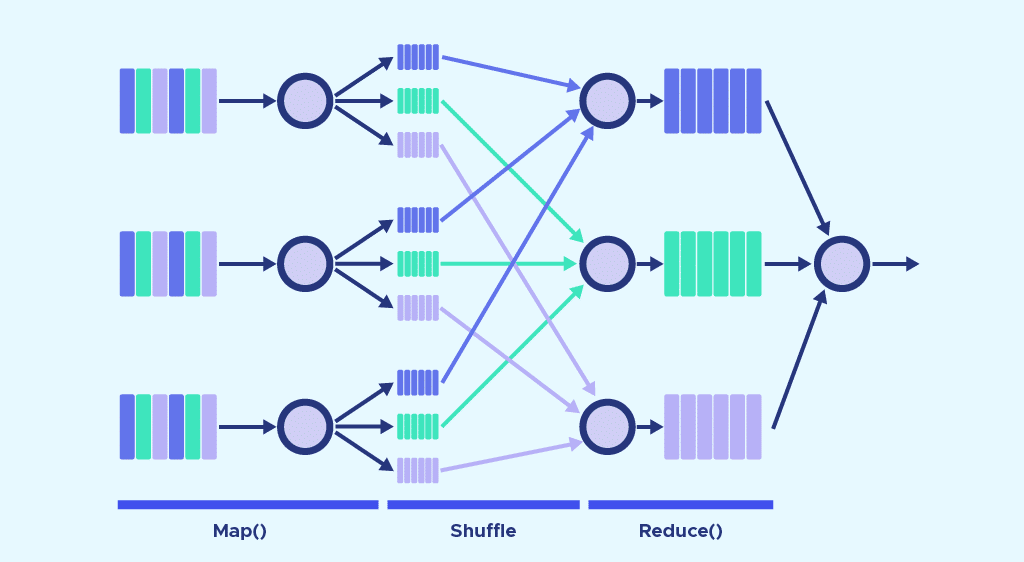
How does MapReduce work?
The operation of MapReduce primarily revolves around two functions: Map and Reduce. To put it simply, Map is used to break down and map the data, while Reduce combines and reduces the data. These functions are executed sequentially. The servers running the Map and Reduce functions are referred to as Mappers and Reducers. However, they can be the same servers.- Map Phase: Input data is divided into chunks, and each chunk is processed independently by a set of mappers. Mappers apply a user-defined function (map function) to transform the input data into a set of key-value pairs.
- Shuffle and Sort Phase: The framework redistributes the output of the mappers based on the keys to group related data together. This phase ensures that all data with the same key is sent to the same reducer.
- Reduce Phase: Reducers receive the grouped data and apply a user-defined function (reduce function) to produce the final output. The reduce function typically aggregates, filters, or performs some computation on the grouped data.
- Output: The final results from the reducers are collected as the output of the MapReduce job.
HDFS (Hadoop Distributed File System)
Hadoop Distributed File System (HDFS) is the storage component of Hadoop. All data stored on Hadoop is stored in a distributed manner across a cluster of machines. The Hadoop Distributed File System (HDFS) is based on the Google File System (GFS) and provides a distributed file system that is designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. It is highly fault-tolerant and is designed to be deployed on low-cost hardware. It provides high throughput access to application data and is suitable for applications having large datasets.What are the components of the Hadoop Distributed File System(HDFS)?
HDFS has two main components, broadly speaking, – data blocks and nodes storing those data blocks.- HDFS Blocks: HDFS breaks down a file into smaller units. Each of these units is stored on different machines in the cluster. This, however, is transparent to the user working on HDFS.
To them, it seems like storing all the data onto a single machine. These smaller units are the blocks in HDFS. The size of each of these blocks is 128MB by default, you can easily change it according to requirement.
There are several perks to storing data in blocks rather than saving the complete file.
- The file itself would be too large to store on any single disk alone. Therefore, it is prudent to spread it across different machines on the cluster.
- It would also enable a proper spread of the workload and prevent the choke of a single machine by taking advantage of parallelism.
- Namenode in HDFS: HDFS operates in a master-worker architecture, this means that there are one master node and several worker nodes in the cluster.
The master node is the Namenode and runs on a separate node in cluster.
- Manages the filesystem namespace which is the filesystem tree or hierarchy of the files and directories.
- Stores information like owners of files, file permissions, etc for all the files.
- It is also aware of the locations of all the blocks of a file and their size.
- Datanodes in HDFS: Datanodes are the worker nodes. They are inexpensive commodity hardware that can be easily added to the cluster. These are the nodes that store actual data in “blocks”. Datanodes are responsible for storing, retrieving, replicating, deletion, etc. of blocks when asked by the Namenode.
- Secondary Namenode in HDFS: The Secondary Namenode regularly merges the Edit Log with the Fsimage, creating check-points for the primary Namenode's file system metadata. This efficient process minimizes downtime during Namenode restarts caused by failures.
YARN
Consider YARN as the brain of your Hadoop Ecosystem. It performs all your processing activities by allocating resources and scheduling tasks. It has two major components, i.e. ResourceManager and NodeManager.- ResourceManager: Think of it as: The traffic controller, managing resources (CPU, memory) and scheduling tasks across the cluster. Responsibilities are:
- Receives job submissions from clients
- Negotiates resource allocation with NodeManagers
- Monitors the progress of running jobs
- NodeManager: Think of it as: The local supervisor on each worker node, overseeing tasks and resource allocation. Main responsibilities are as follows:
- Starts and monitors tasks assigned by the ResourceManager
- Manages resources on the local node (CPU, memory, network)
- Reports resource usage and task progress to the ResourceManager
Key concepts
Hadoop Cluster?: A Hadoop cluster is a network of computers or nodes working together to handle large datasets efficiently. Think of it as a team of specialists, each with their own expertise, tackling a massive project collaboratively. In this analogy, the computers are the specialists, and the data is the project.
Hadoop daemons: In the world of Hadoop, daemons are like the tireless workers behind the scenes, ensuring everything runs smoothly and efficiently. Each daemon has a specific role in managing data storage, processing, and resource allocation across the cluster. The core hadoop daemons are:
- NameNode
- DataNode
- Secondary NameNode
- ResourceManager
- NodeManagers
Nodes:
Nodes are the machines that make up a cluster. They can be physical or virtual servers in a cloud computing environment. These nodes are connected with each other through LAN (Local Area Network). The nodes in a cluster share the data, work on the same task and this nodes are good enough to work as a single unit means all of them to work together. The nodes in a Hadoop cluster can be divided into two types:- Master Node: This is the node that manages the overall operation of the cluster. It is responsible for assigning tasks to other nodes, monitoring their progress, and handling failures. The master node in a Hadoop cluster is typically a
NameNode (NN)in the case of HDFS (Hadoop Distributed File System). - Worker (slave) Nodes: These are the nodes that perform the actual processing of data. Each worker node is responsible for executing tasks assigned by the master node. In the context of HDFS, the worker nodes are called
DataNodes (DN).
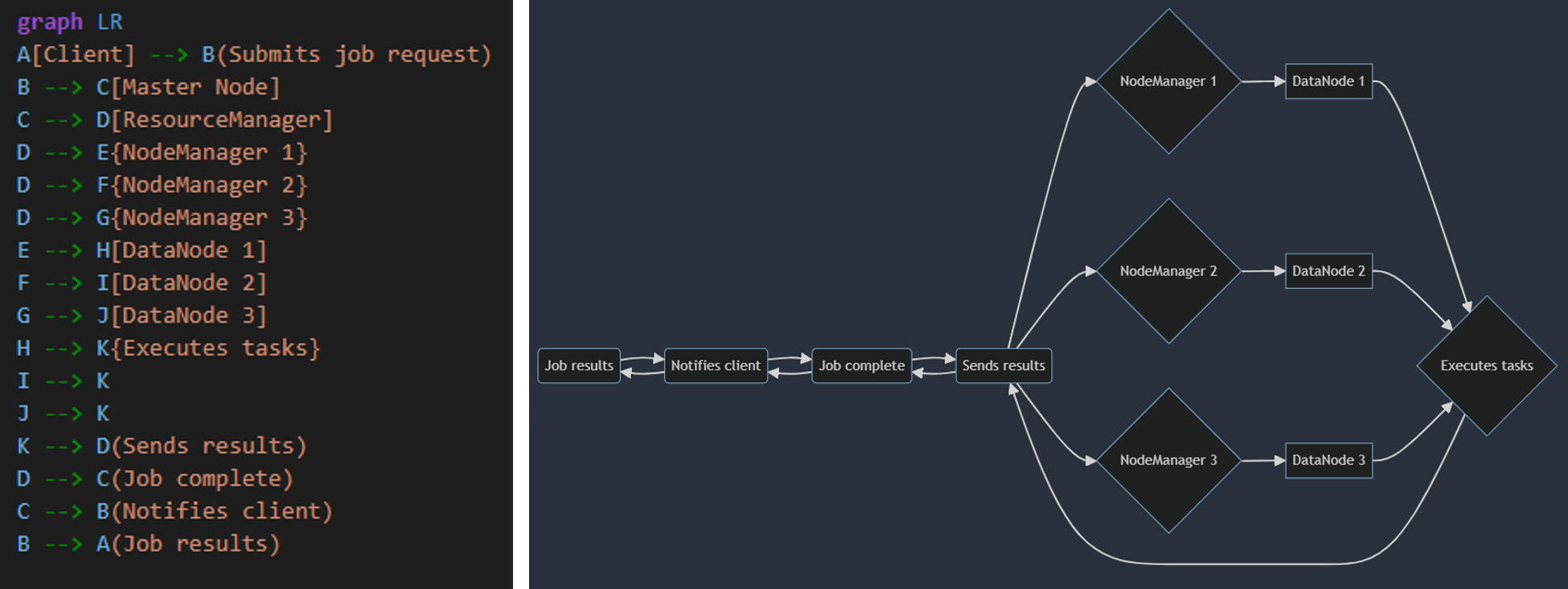
- Client: Submits a job request to the Master Node.
- Master Node: Receives the job request and coordinates its execution.
- ResourceManager: Manages resources (CPU, memory) across the cluster and allocates them to tasks.
- NodeMangers: Run on each worker node, managing tasks and reporting progress to the ResourceManager.
- DataNodes: Store data blocks and provide access to them for task execution.
- Tasks: Individual units of work that make up a job, executed on worker nodes.
- Results: Generated by tasks and sent back to the ResourceManager, eventually reaching the client.
Types of Hadoop clusters There are mainly two types of Hadoop clusters:
- Single Node Hadoop Cluster: This type consists of a single machine running all the essential Hadoop daemons (NameNode, DataNode, ResourceManager, NodeManager) on its own.
Pros:
- Simple setup: Easy to install and configure, ideal for testing or learning.
- Low cost: Requires only one machine, minimizing hardware expenses.
- No additional infrastructure: No need for complex network configurations or cluster management tools.
Cons:
- Limited scalability: Cannot handle large datasets effectively due to resource constraints of a single machine.
- No fault tolerance: A single point of failure – if the machine fails, the entire cluster goes down.
- Not suitable for production: Primarily used for small-scale deployments or educational purposes.
- Multiple Node Hadoop Cluster: This type distributes the workload across multiple machines, each having specific roles (master nodes, worker nodes).
Pros:
- Scalability: Easily add more nodes to handle growing datasets and processing demands.
- Fault tolerance: Distributed architecture ensures cluster functionality even if individual nodes fail.
- High performance: Utilizes combined resources of multiple machines for faster processing.
Cons:
- Complex setup: Requires more configuration and technical expertise to manage.
- Higher cost: Hardware and software costs increase with the number of nodes.
- Additional infrastructure: Requires network setup, cluster management tools, and potentially dedicated resources.
Single and multi-node: Next question one can ask is how to Choose between single-node and multi-node? The choice depends on specific needs:
- For small datasets, basic testing, or learning purposes, a single-node cluster might suffice.
- For production environments with larger datasets, complex workloads, and scalability requirements, a multi-node cluster is essential.
Apache Ecosystem
The Hadoop ecosystem includes a wide variety of open source Big Data tools. These various tools complement Hadoop and enhance its Big Data processing capability. Among the most popular, Apache Hive is a Data Warehouse dedicated to processing large datasets stored in HDFS. The Zookeeper tool automates failovers and reduces the impact of a NameNode failure.| Name | Description |
|---|---|
| Hadoop Distributed File System (HDFS): | HDFS is the primary storage system for Hadoop, designed to store large files across multiple nodes in a distributed manner. |
| Apache Airflow: | Apache Airflow is an open-source platform to programmatically author, schedule, and monitor workflows. It allows you to define a directed acyclic graph (DAG) of tasks and their dependencies, enabling the automation of complex data workflows. |
| Apache NiFi: | A data integration and automation tool that facilitates the flow of data between systems. |
| Apache ZooKeeper: | A distributed coordination service that provides distributed synchronization and helps in managing configuration information and naming services for distributed systems. |
| MapReduce | The original programming model for distributed processing in Hadoop, as previously mentioned. |
| Apache Kafka: | A distributed streaming platform for building real-time data pipelines and streaming applications. |
| Apache Spark: | A fast and general-purpose cluster computing framework that supports in-memory processing and provides APIs for various programming languages. |
| Apache Flink: | A stream processing framework for big data processing and analytics. |
| Apache Hive | A data warehousing and SQL-like query language for Hadoop. It allows users to query and analyze large datasets stored in Hadoop |
| Apache Pig | A high-level platform and scripting language built on top of Hadoop, designed for processing and analyzing large datasets |
| Apache HBase | A distributed, scalable, and NoSQL database that provides real-time read/write access to large datasets. |
| Apache Sqoop | A tool for efficiently transferring bulk data between Apache Hadoop and structured data stores such as relational databases |
| Apache Flume | A distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. |
| Apache Oozie | A workflow scheduler for managing Hadoop jobs, allowing the coordination of various tasks in a Hadoop ecosystem. |
| Apache Zeppelin | A web-based notebook for data analytics and visualization, supporting multiple languages including SQL, Python, and Scal. |
| Apache Mahout: | A machine learning library and framework for building scalable and distributed machine learning algorithms. |
| Apache Accumulo: | A NoSQL database that is built on top of Apache Hadoop and based on Google's BigTable design. |
| Apache Drill: | A schema-free SQL query engine for Hadoop, NoSQL databases, and cloud storage. |
| Apache Knox: | A gateway for providing secure access to the Hadoop ecosystem through REST APIs. |
| Apache Ranger: | A framework for managing access and authorization to various components within the Hadoop ecosystem. |
| Apache Atlas: | A metadata management and governance framework for Hadoop, providing a scalable and extensible solution for cataloging and managing metadata. |
| Apache Ambari: | A management and monitoring platform that simplifies the provisioning, managing, and monitoring of Hadoop clusters. |
| Apache Kylin: | An open-source distributed analytics engine designed for OLAP (Online Analytical Processing) on big data. |
| Apache Livy: | A REST service for Apache Spark that enables easy interaction with Spark clusters over a web interface. |
| Apache Superset: | A modern, enterprise-ready business intelligence web application that facilitates data exploration and visualization. |
References
- Apache Spark™ Official Documentation.
- Databricks Learning Academy.
- Spark by Examples.
Some other interesting things to know:
- Visit my website on For Data, Big Data, Data-modeling, Datawarehouse, SQL, cloud-compute.
- Visit my website on Data engineering