
Apache Pyspark
Introduction to Apache pySpark
PySpark is the Python API for Apache Spark, an open-source, distributed computing framework designed for large-scale data processing. It allows you to leverage the power of Spark from the familiar and approachable Python environment. It provides Python bindings that allow developers to create, test, and deploy applications using the Spark API.Summary Apache Spark
- Definition: Apache Spark is an Open source analytical processing engine for large-scale powerful distributed data processing and machine learning applications.
Apache Spark 3.5 is a framework that is supported in Scala, Python, R Programming, and Java. Below are different implementations of Spark.
- Spark - Default interface for Scala and Java
- PySpark – Python interface for Spark
- SparklyR – R interface for Spark.
- Features of Apache Spark:
- In-memory computation
- Distributed processing using parallelize
- Can be used with many cluster managers (Spark, Yarn, Mesos e.t.c)
- Fault-tolerant
- Immutable
- Lazy evaluation
- Cache & persistence
- Inbuild-optimization when using DataFrames
- Supports ANSI SQL
- Advantages of Apache Spark:
- Spark is a general-purpose, in-memory, fault-tolerant, distributed processing engine that allows you to process data efficiently in a distributed fashion.
- Applications running on Spark are 100x faster than traditional systems.
- There are so many benefits from using Spark for data ingestion pipelines.
- Using Spark we can process data from Hadoop HDFS, AWS S3, Databricks DBFS, Azure Blob Storage, and many file systems.
- Spark also is used to process real-time data using Streaming and Kafka.
- Using Spark Streaming you can also stream files from the file system and also stream from the socket.
- Spark natively has machine learning and graph libraries.
- Provides connectors to store the data in NoSQL databases like MongoDB.
- Apache Spark Architecture:
Spark works in a master-slave architecture where the master is called the “Driver” and slaves are called “Workers”. When you run a Spark application, Spark Driver creates a context that is an entry point to your application, and all operations (transformations and actions) are executed on worker nodes, and the resources are managed by Cluster Manager.
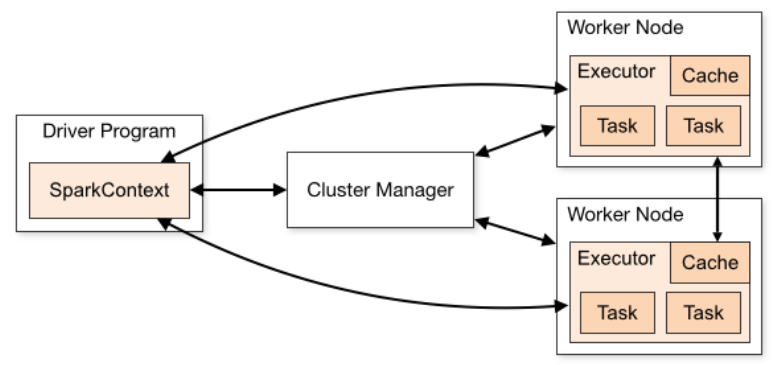
- Cluster Manager Types: Standalone, Apache Mesos, Hadoop YARN, Kubernetes, local (for master() in order to run Spark on local computer).
- Spark Modules: Spark Core, Spark SQL, Spark Streaming, Spark MLlib, Spark GraphX
- Spark Core: Spark Core is the main base library of Spark which provides the abstraction of how distributed task dispatching, scheduling, basic I/O functionalities etc.
- SparkSession: It is an entry point to underlying Spark functionality in order to programmetically use Spark RDD, DataFrame, and Dataset. It's object
sparkis default available in spark-shell. The initial step in a Spark program involving RDDs, DataFrames, or Datasets would be to create a SparkSession instance. The Sparksession will be created usingSparkSession.builder().
If you're using SparkSession, which is the entry point to Spark SQL, you can work with DataFrames and Datasets, which provide higher-level abstractions and optimizations compared to RDDs. Here are some common tasks you can perform with SparkSession:from pyspark.sql import SparkSession # Create a SparkSession object spark = SparkSession.builder \ .appName("YourAppName") \ .master("local[*]") \ .getOrCreate() spark # to call spark- Read and write data: SparkSession provides methods to read data from various sources such as Parquet, JSON, CSV, JDBC, Avro, ORC, and many more. Similarly, you can write data to different formats and locations.
For example:
df = spark.read.csv("file.csv")anddf.write.parquet("output.parquet") - Create DataFrames: You can create DataFrames from existing RDDs, lists, dictionaries, or by applying transformations on other DataFrames. For example:
from pyspark.sql import Row data = [(1, "Alice"), (2, "Bob")] rdd = sc.parallelize(data) row_rdd = rdd.map(lambda x: Row(id=x[0], name=x[1])) df = spark.createDataFrame(row_rdd) - SQL queries: SparkSession allows you to run SQL queries on DataFrames using the sql() method. For example:
df.createOrReplaceTempView("people") result = spark.sql("SELECT * FROM people WHERE age > 20") - DataFrame operations: You can perform various operations on DataFrames like
select(),filter(),join(),orderBy(),agg()etc. For example:result = df.select("name").filter(df.age > 20).orderBy(df.name) - Window functions: You can use window functions for advanced analytics tasks like ranking, lead/lag analysis, etc. For example:
from pyspark.sql.window import Window from pyspark.sql.functions import rank window = Window.partitionBy("department").orderBy("salary") result = df.withColumn("rank", rank().over(window)) - Machine learning: We can use Spark MLlib, a scalable machine learning library, to train and apply machine learning models on DataFrames. For example:
from pyspark.ml.classification import LogisticRegression lr = LogisticRegression(featuresCol="features", labelCol="label") model = lr.fit(train_data) predictions = model.transform(test_data) - Streaming data:We can process streaming data using Spark Structured Streaming, which provides high-level APIs for streaming processing. For example:
stream_df = spark.readStream.format("kafka").option("kafka.bootstrap.servers", "host:port").load()
- Read and write data: SparkSession provides methods to read data from various sources such as Parquet, JSON, CSV, JDBC, Avro, ORC, and many more. Similarly, you can write data to different formats and locations.
For example:
- Spark Context: It is also a entry point to Spark and PySpark. Before SparkSession 2.0, it was the main entry point.
Creating SparkContext was the first step to the program with RDD and to connect to Spark Cluster. It’s object sc by default available in
spark-shell. Since Spark 2.0, when we createSparkSession,SparkContextobject is by default created and it can be accessed usingspark.sparkContext.
Once the spark context is created, we can do following things:from pyspark.sql import SparkSession # Create a SparkSession spark = SparkSession.builder \ .appName("YourAppName") \ .master("local[*]") \ .getOrCreate() # Access the SparkContext from the SparkSession sc = spark.sparkContext- Parallelize data: We can parallelize an existing collection in your driver program (e.g., a list or array) using the
parallelize()method. This will distribute the data across the nodes in your Spark cluster and create an RDD.rdd = sc.parallelize(data) - Read data from external sources: We can read data from various external sources such as HDFS, S3, HBase, or any supported data source using the methods provided by SparkContext, such as
textFile()for reading text files.text_rdd = sc.textFile("hdfs://path/to/file.txt") - Transformations: can perform various transformations on RDDs, such as
map(),filter(),flatMap(),reduceByKey(), etc., to process and manipulate the data. For example:squared_rdd = rdd.map(lambda x: x * x) - Caching: We can cache RDDs in memory to speed up iterative or interactive computations by using the
cache()method. For example:rdd.cache() - Accumulators: We can can use accumulators to aggregate information across all tasks, such as counting occurrences of certain events. For example:
accumulator = sc.accumulator(0).
- Parallelize data: We can parallelize an existing collection in your driver program (e.g., a list or array) using the
- SparkContext (sc):
- SparkContext is the entry point to Spark functionality and represents the connection to a Spark cluster. It coordinates the execution of operations on the cluster.
- It provides access to the underlying Spark functionality, including RDDs (Resilient Distributed Datasets), which are the fundamental data abstraction in Spark.
- SparkContext is primarily used for low-level operations and interactions with RDDs, such as creating RDDs, performing transformations, and executing actions.
- SparkSession (spark):
- SparkSession, introduced in Spark 2.x, is a higher-level abstraction on top of SparkContext and provides a unified entry point to Spark SQL, DataFrame, and Dataset APIs.
- It is the recommended way to interact with Spark in modern Spark applications, as it provides a more user-friendly and consistent interface for working with structured data.
- SparkSession encapsulates SparkContext and provides additional functionalities, including reading and writing structured data from various sources, running SQL queries, and performing DataFrame operations.
- SparkSession also manages the underlying SparkContext internally, so there's no need to create a SparkContext explicitly when using SparkSession.
Difference between SparkContext and SparkSession
PySpark methods
| Functionality | PySpark Method |
|---|---|
| SparkSession |
|
| Reading and Writing Data: |
|
| DataFrame Operations: |
|
| Transformations: |
|
| Actions |
|
| SQL Queries: |
|
| Data Aggregation and Summary |
|
| Data Cleaning and Handling: |
|
| Window Functions: |
|
| Caching |
|
| Machine Learning: |
|
| Statistical Functions: |
|
| Time Series and Date Functions: |
|
| Graph Processing (GraphFrames): |
|
| User-Defined Functions (UDFs): |
|
Codes on GitHub
For the details on how pyspark can be used to do data analytics of a large dataset is available at my GitHub repository. In this repository, I have done analysis on some examples datasets using Pyspark Dataframe and RDD methods.RDD's Resilient Distributed Datasets (RDDs)
The RDD structure is the elementary structure of Spark. It is flexible and optimal in performance for any linear operation. However, this structure has limited performance when it comes to non-linear operations.SparkContext:
SparkContext is a crucial entry point for any Spark functionality in Apache Spark applications. It coordinates the execution of Spark jobs
and manages the resources allocated for these jobs. In Spark versions before 2.0, it was the main entry point for Spark, but in later versions,
SparkSession is typically used, which internally creates a SparkContext object.
- Definition:
SparkContextis the main entry point for Spark functionality in Spark applications. - Purpose: It coordinates the execution of Spark jobs and manages the resources allocated for these jobs.
- Usage: In older versions of Spark, it was directly created by developers. In newer versions, it's often implicitly created as part of a
SparkSession.
SparkContext, we typically create an instance of it in the Spark application code. However, in newer versions of Spark (2.0 and above), it's recommended to use
SparkSession instead, which internally manages the SparkCOntext.
- Using SparkContext:
In this example:from pyspark import SparkContext # Create a SparkContext object sc = SparkContext("local", "MyApp")- "local" specifies that Spark should run in local mode using a single thread.
- "MyApp" is a name for your Spark application.
- Using SparkSession: For newer versions of Spark, you typically use SparkSession, which internally creates a SparkContext. Here's how you do it:
In this case:from pyspark.sql import SparkSession # Create a SparkSession object spark = SparkSession \ .builder \ .master("local") \ .appName("MyApp") \ .getOrCreate() spark- "MyApp" is also the name for your Spark application.
- getOrCreate() method ensures that if a SparkSession already exists, it returns that session; otherwise, it creates a new one.
SparkContext can also be created using SparkSession:# Creating SparkContext through SparkSession from pyspark.sql import SparkSession # Create a SparkContext object spark = SparkSession.builder \ .appName("MyApp") \ .getOrCreate() # Access SparkContext from sparksession sc = spark.SparkContext
Example:
ThetextFile method of SparkContext allows to load a CSV file into a RDD.
rdd = sc.textFile("path_to_file.ext")take(5) function:
rdd.take(5)count() can be used:
count = rdd.count()- Map: The map operation applies a function to each element in a dataset and produces a new dataset of the same size. It transforms each element into another element based on the function provided. The map operation is typically used for tasks like data cleaning, transformation, or feature extraction.
- Reduce: The reduce operation combines elements of a dataset pairwise using a given function until a single result is obtained. It repeatedly applies the function to pairs of elements until only one element remains. The reduce operation is commonly used for tasks like aggregation, summarization, or finding totals.
# Applying a map operation to double each element in a list
numbers = [1, 2, 3, 4, 5]
doubled_numbers = list(map(lambda x: x * 2, numbers))
print(doubled_numbers)
Output: [2, 4, 6, 8, 10]
from functools import reduce
# Applying a reduce operation to find the sum of elements in a list
numbers = [1, 2, 3, 4, 5]
total_sum = reduce(lambda x, y: x + y, numbers)
print(total_sum)
Output: 15The RDD works very well for "line-by-line" operations, which is why the
mao and reduce methods are extremely effective for these calculations.
Applying successively the map method and then the reduceByKey method allows us to cleverly summarize our data.
rdd.map(lambda x: (x[7]:1)).reduceByKey(lambda x,y:x+y)
DataFrame for structured data:
The RDD structure is not optimized for column tasks or Machine learning. The
DataFrame structure was created to meet this need.
It uses the underlying bases of a RDD but it has been structured in columns and rows in a SQL structure in a form inspired by the DataFrame of the python pandas module.
Advantages: The DataFrame structure has two main Advantages. First of all, this structure is similar to the pandas DataFrame and is therefore easy to learn. It is also efficient. A DataFrame om PySpark is as fast as a DataFrame in scala and it is the most optimized distributed structure in machine learning.
Let's take a example to understand the basics of this:- Let's first build the spark session:
# Importing Spark Session and SparkContext from pyspark.sql import SparkSession from pyspark import SparkContext # Definition of a SparkContext SparkContext.getOrCreate() # Definition of a SparkSession spark = SparkSession \ .builder \ .master("local") \ .appName("Introduction to DataFrame") \ .getOrCreate() spark For more details you can always go to my github repo: Pyspark repo.
For more details you can always go to my github repo: Pyspark repo.
References
- Official Documentation
- Databricks Learning Academy
- Spark by Examples
- Datacamp tutorial.
- For databricks, you can look at tutorial videos on youtube at youtube video by Bryan Cafferky, writer of the book "Master Azure Databricks". A great playlist for someone who just want to learn about the big data analytics at Databricks Azure cloud platform.
- See the video for pyspark basics by Krish Naik. Great video for starter.
- Great youtube on Apache spark one premise working.
Some other interesting things to know:
- Visit my website on For Data, Big Data, Data-modeling, Datawarehouse, SQL, cloud-compute.
- Visit my website on Data engineering