
Apache spark: Big data processing
Introduction to Apache Spark
Apache Spark™ is an open-source, distributed computing system for processing and analyzing large datasets. It was initially developed in 2012 at the AMPLab at UC Berkeley and later donated to the Apache Software Foundation.- Spark's primary feature is its ability to perform data processing in-memory, which makes it significantly faster than Apache Hadoop® for certain types of workloads. Spark supports various types of big data workloads, including batch processing, interactive queries, streaming, machine learning, and graph processing.
- On the other hand, Apache Hadoop® is a platform that was first developed in 2006 and is used for distributed storage and processing of large datasets. Hadoop® is built using the MapReduce programming model, which is based on the idea of mapping and reducing data to process it in parallel across a distributed cluster of computers. Hadoop® is known for its fault-tolerance, scalability, and cost-effectiveness.
- Imagine a powerful engine built for speed and endurance. That's essentially what Spark is. It's an open-source, unified analytics engine designed to process massive datasets efficiently and at lightning speed. It achieves this through its unique distributed architecture, where tasks are split across multiple machines, working in parallel to crunch through your data.
How does Spark work?
Spark's operational model adheres to the hierarchical primary-secondary principle, commonly known as the master-slave principle. The Spark driver functions as the master node, overseen by the cluster manager, which, in turn, manages the slave nodes and directs data analyses to the client. The distribution and monitoring of executions and queries are facilitated through the SparkContext, established by the Spark driver, collaborating with cluster managers like Spark, YARN, Hadoop, or Kubernetes. The Resilient Distributed Datasets (RDDs) play a pivotal role in this process.
Spark dynamically determines resource utilization for data querying or storage, deciding where queried data is directed. The engine's ability to process data directly in the memory of server clusters dynamically reduces latency and ensures rapid performance. Additionally, the implementation of parallel work steps and the utilization of both virtual and physical memory contribute to its efficiency.
Apache Spark also processes data from various data stores . These include the Hadoop Distributed File System (HDFS) and relational data storage such as Hive or NoSQL databases. In addition, there is performance-enhancing in-memory or hard-disk processing - depending on how large the data sets in question are
- MapReduce
- HDFS(Hadoop Distributed File System)
- YARN(Yet Another Resource Negotiator)
- Common Utilities or Hadoop Common
Difference between Hadoop® and Apache Spark™
- Performance: Spark is generally faster than Hadoop® for data processing tasks because it performs computations in-memory, reducing the need to read and write data to disk. Spark can be up to 100 times faster than Hadoop® for certain workloads.
- Cost: Spark can be more expensive than Hadoop® because it requires more memory to perform in-memory computations. Hadoop®, on the other hand, is known for its cost-effectiveness as it can run on commodity hardware.
- Machine Learning Algorithms: Spark provides built-in machine learning algorithms in its MLlib library, which can be used for regression, classification, clustering, and other machine learning tasks. Hadoop® does not have built-in machine learning libraries, but it can be integrated with other machine learning frameworks such as Apache Mahout.
- Data Processing: Hadoop® is primarily used for batch processing, which involves processing large datasets in job lots. Spark supports batch processing, but it also supports interactive queries, streaming, and graph processing.
- Programming Languages: Hadoop® is primarily written in Java, and its MapReduce programming model is based on Java. Spark supports programming in Java, Scala, Python, and R, making it more accessible to a wider range of developers.
Some key concepts of Apache Spark™
- Distributed Processing: Unlike traditional methods that process data on a single machine, Spark distributes tasks across multiple machines (nodes) in a cluster. This allows it to handle massive datasets efficiently by dividing the work and processing it in parallel. Think of it as having many chefs working on different parts of a large meal instead of just one.
- Resilience: Spark is designed to be fault-tolerant. If a node fails, the work is automatically reassigned to other nodes, ensuring your processing continues uninterrupted. This is like having backup chefs ready to step in if someone gets sick.
- In-Memory Computing: Spark stores frequently accessed data in memory for faster processing compared to reading it from disk. This is like having your ingredients readily available on the counter instead of searching the pantry every time you need something.
- Lineage (i.e. version): Spark keeps track of how data is transformed, allowing you to trace the origin and understand how results were obtained. This is like having a recipe that shows you each step involved in creating the final dish.
- APIs: Spark provides APIs in various languages like Python, Java, Scala, and R. This allows you to choose the language you're most comfortable with and write code in a familiar syntax. It's like having different tools (spatulas, whisks, etc.) that work with the same ingredients.
- Functional Programming: Spark heavily utilizes functional programming concepts like immutability and lazy evaluation. This makes code cleaner, easier to reason about, and more resistant to errors. Think of it as following precise instructions without modifying the ingredients themselves.
Key Features
Apache Spark is a significantly faster and more powerful engine than Apache Hadoop or Apache Hive . It processes jobs 100 times faster when processing occurs in memory and 10 times faster when processing occurs on disk compared to Hadoop's MapReduce. Spark therefore offers companies cost-reducing and efficiency-increasing performance. What is particularly interesting about Spark is its flexibility. This means that the engine can not only be run independently, but also in Hadoop clusters controlled via YARN. It also enables developers to write applications for Spark in various programming languages . Not only SQL , but also Python, Scala, R or Java come into question. Other special features of Spark: It does not have to be set up on the Hadoop file system, but can also be operated with other data platforms such as AWS S3, Apache Cassandra or HBase . In addition, when specifying the data source, it processes both batch processes such as Hadoop as well as stream data and various workloads with almost identical code. Using an interactive query process, current and historical real-time data, including analysis, can be distributed across multiple layers on the hard drive and memory and processed in parallel. Summary of the key features are as follows:- Speed: Spark performs in-memory processing, making it much faster than its predecessor, MapReduce. It achieves high performance through advanced DAG (Directed Acyclic Graph) execution engine.
- Ease of Use: Spark supports multiple programming languages, including Scala, Java, Python, and R. Its high-level APIs make it easy to use for both batch processing and real-time data processing.
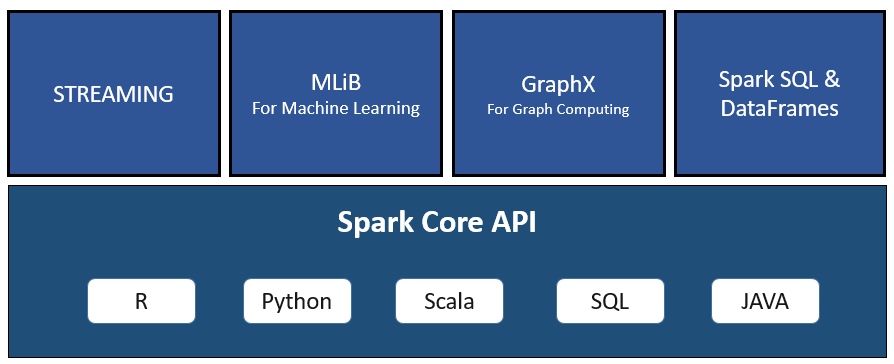
- Versatility: Spark's ecosystem includes libraries for data analysis, machine learning (MLlib), graph processing (GraphX), and stream processing (Structured Streaming). This versatility makes it a comprehensive solution for various data-related tasks.
- Fault Tolerance: Spark provides fault tolerance through lineage information and recomputation, ensuring that tasks are re-executed in case of node failures.
- Compatibility: It can run on various cluster managers, such as Apache Mesos, Hadoop® YARN, or Kubernetes, making it compatible with different big data environments.
Components of Apache Spark™
Spark Core is the fundamental component of Apache Spark™, serving as the project's foundation. It offers distributed task dispatching, scheduling, and basic I/O functionalities. Spark Core provides an application programming interface (API) for multiple programming languages like Java, Python, Scala, .NET, and R. This API is centered around the Resilient Distributed Datasets (RDD) abstraction. The Java API, while primarily for JVM languages, can also be used with some non-JVM languages that can connect to the JVM, such as Julia.- Spark Core: Spark Core is the underlying general execution engine for spark platform that all other functionality is built upon. It provides In-Memory computing and referencing datasets in external storage systems. It provides the basic functionality of Spark, including task scheduling, memory management, and fault recovery.
- Spark SQL: Spark SQL is a component on top of Spark Core that introduces a new data abstraction called SchemaRDD, which provides support for structured and semi-structured data. Allows for querying structured data using SQL as well as Spark's built-in DataFrame API.
- Spark Streaming: Spark Streaming leverages Spark Core's fast scheduling capability to perform streaming analytics. It ingests data in mini-batches and performs RDD (Resilient Distributed Datasets) transformations on those mini-batches of data. Enables scalable, high-throughput, fault-tolerant stream processing of live data streams.
- Spark DataFrames: High-level data structures for manipulating data like a spreadsheet.
- Spark MLlib (Machine Learning Library): A distributed machine learning framework for building scalable and robust machine learning models. Spark MLlib is nine times as fast as the Hadoop disk-based version of Apache Mahout (before Mahout gained a Spark interface).
- Spark GraphX: GraphX is a distributed graph-processing framework on top of Spark. It provides an API for expressing graph computation that can model the user-defined graphs by using Pregel abstraction API. It also provides an optimized runtime for this abstraction.
- Spark Structured Streaming: Allows users to express streaming computations the same way as batch computations, providing unified processing for both.
Use Cases
- Big Data Processing: Spark is widely used for processing and analyzing large datasets efficiently.
- Machine Learning: MLlib simplifies the development of scalable machine learning applications.
- Graph Processing: GraphX enables the processing of large-scale graph data.
- Real-time Analytics: Spark Streaming and Structured Streaming support real-time analytics.
Spark Architecture
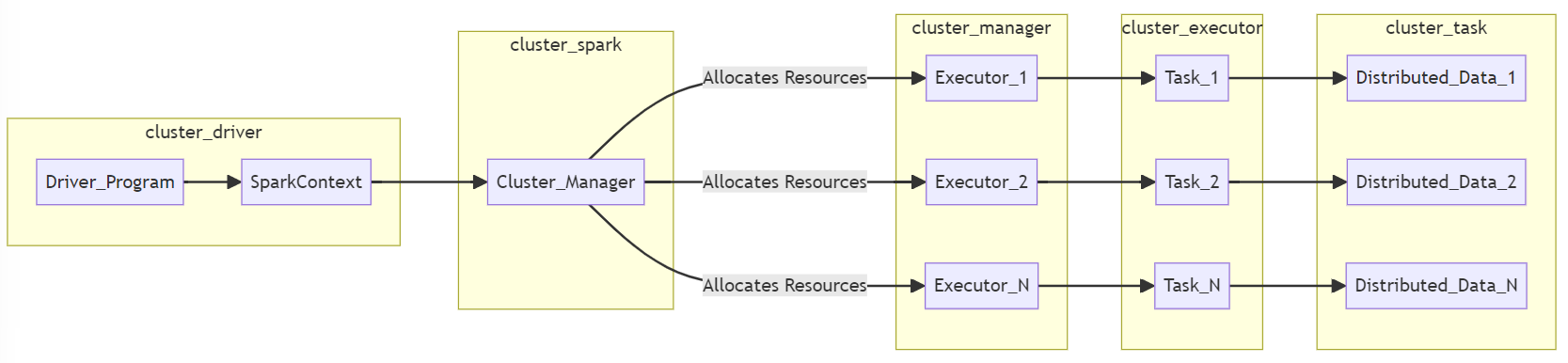
Apache Spark's architecture is designed for efficient and scalable processing of large datasets. It achieves this through two main pillars:- Master-Slave Architecture:
- Master (Driver): Submits applications, coordinates task scheduling, and manages communication between components. Think of it as the conductor of an orchestra, overseeing the entire performance.
- Slaves (Executors): Worker nodes distributed across the cluster, carrying out the actual computations on partitioned data. Imagine them as the different sections of the orchestra, each playing their assigned parts.
- Data Abstraction:
- Resilient Distributed Datasets (RDDs): Immutable, fault-tolerant collections of data distributed across the cluster. RDDs are the fundamental unit of data in Spark and can be created from various sources like files, databases, or other RDDs. Think of them as sheet music distributed to each section of the orchestra, ensuring everyone plays the same song simultaneously.
- Driver Program:
- The entry point of any Spark application.
- Contains the main function and creates a SparkContext to coordinate the execution of tasks.
- Cluster Manager:
- Manages resources across the cluster.
- Common cluster managers include Apache Mesos, Hadoop YARN, and Spark's standalone cluster manager.
- SparkContext:
- Created by the driver program and coordinates the execution of tasks on the cluster.
- Communicates with the cluster manager to acquire resources and manage the execution of tasks.
- Distributed Data:
- Data is distributed across the cluster in partitions.
- Resilient Distributed Datasets (RDDs) or DataFrames represent distributed collections of data.
- Executor:
- Each worker node in the cluster has an executor.
- Executes tasks assigned by the SparkContext and manages the data stored on that node.
- Task:
- The smallest unit of work in Spark.
- Executed on an executor and performs operations on the partitions of the distributed data.
- Job:
- A collection of tasks that are submitted to Spark for execution.
- Jobs are divided into stages based on the transformations and actions applied to the data.
- Stage:
- A set of tasks that can be executed in parallel without shuffling data between them.
- Stages are determined by the transformations in the application.
- RDD lineage and DAG:
- RDD lineage records the sequence of transformations applied to construct an RDD.
- Directed Acyclic Graph (DAG) is a logical representation of the sequence of stages and tasks.
- Shuffling:
- Occurs when data needs to be redistributed across the cluster, typically between stages.
- Can be an expensive operation in terms of performance.
- Broadcasting:
- Efficiently sends read-only variables to all the worker nodes, reducing data transfer overhead.
#!graph lr
graph LR
subgraph cluster_driver
Driver_Program --> SparkContext
end
subgraph cluster_spark
SparkContext --> Cluster_Manager
end
subgraph cluster_manager
Cluster_Manager --> |Allocates Resources| Executor_1
Cluster_Manager --> |Allocates Resources| Executor_2
Cluster_Manager --> |Allocates Resources| Executor_N
end
subgraph cluster_executor
Executor_1 --> Task_1
Executor_2 --> Task_2
Executor_N --> Task_N
end
subgraph cluster_task
Task_1 --> Distributed_Data_1
Task_2 --> Distributed_Data_2
Task_N --> Distributed_Data_N
end
Resilient Distributed Datasets (RDD)
Resilient Distributed Datasets (RDD) is a fundamental data structure of Spark. It is an immutable distributed collection of objects. Each dataset in RDD is divided into logical partitions, which may be computed on different nodes of the cluster. RDDs can contain any type of Python, Java, or Scala objects, including user-defined classes. There are two ways to create RDDs:- parallelizing an existing collection in your driver program or
- referencing a dataset in an external storage system, such as a shared file system, HDFS, HBase, or any data source offering a Hadoop Input Format.
Data sharing is slow in MapReduce due to replication, serialization, and disk IO. Most of the Hadoop applications, they spend more than 90% of the time doing HDFS read-write operations. Recognizing this problem, researchers developed a specialized framework called Apache Spark. The key idea of spark is Resilient Distributed Datasets (RDD); it supports in-memory processing computation. This means, it stores the state of memory as an object across the jobs and the object is sharable between those jobs. Data sharing in memory is 10 to 100 times faster than network and Disk
References
- Apache Spark™ Official Documentation.
- Databricks Learning Academy.
- Spark by Examples.
- Beneath RDD(Resilient Distributed Dataset) in Apache Spark
Some other interesting things to know:
- Visit my website on For Data, Big Data, Data-modeling, Datawarehouse, SQL, cloud-compute.
- Visit my website on Data engineering