
Web Scraping: A Powerful Tool for Data Acquisition
Introduction
In the vast and ever-expanding world of the internet, data is a precious commodity. It fuels businesses, informs decision-making, and shapes the way we interact with the digital landscape. However, extracting meaningful information from the vast sea of web pages can be a daunting task. This is where web scraping comes into play.What is Web Scraping?
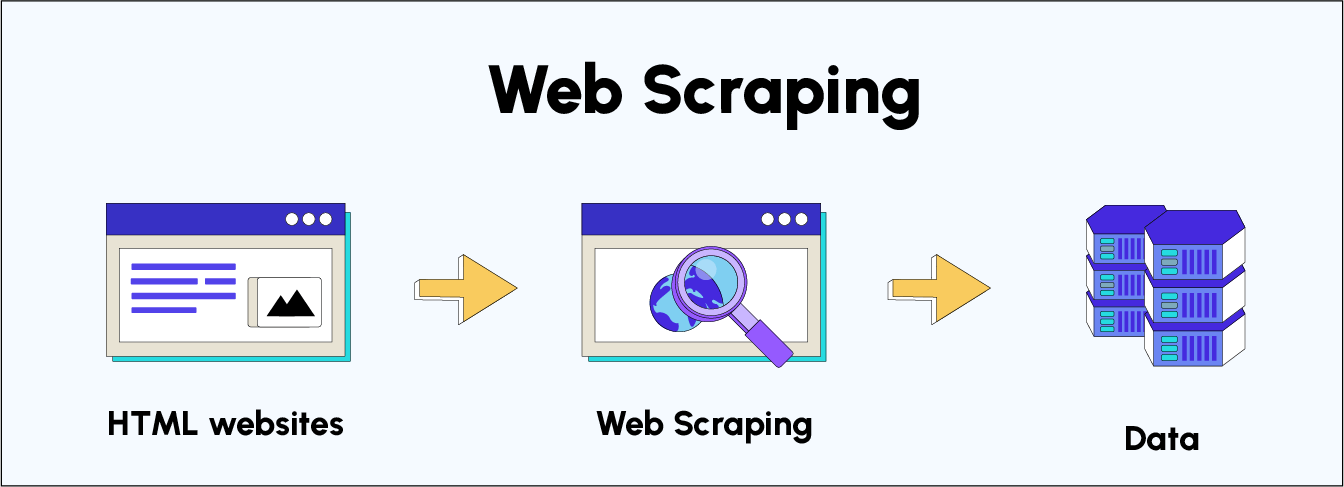
Web scraping, also known as web harvesting or web data extraction, is the automated process of extracting data from websites. It involves using software tools to mimic a human user's browsing behavior, navigating through websites and extracting the desired information. This information can then be saved in a structured format, such as a spreadsheet or database, for further analysis and use.What's the web?
When we surf the web, what we see of a website - its content and visuals - is coded in programming languages that belong to a same domain: web development. While there are many languages and frameworks in this field today, we can simplify its code by using 3 programming languages: HTML, CSS and Javascript. It is the combination of these 3 languages that constitutes the source code of the web pages accessible from our browser. To become an expert in Web Scraping, we need to master the basics of web development.
How Does Web Scraping Work?
- Crawling: The first step in web scraping is to crawl the target website or websites. Crawlers are bots or scripts that systematically visit and download web pages, following links to discover new content. This process allows the scraper to map out the website's structure and identify the pages containing the desired data.
- Parsing: Once the crawler has downloaded a web page, the scraper analyzes its HTML code to identify the specific elements that contain the relevant information. This involves understanding HTML tags, attributes, and CSS styles.
- Extraction: Using the parsed information, the scraper extracts the desired data from the web page. This may involve extracting text, images, links, or other elements.
- Storage: Finally, the extracted data is stored in a structured format, such as a CSV file, JSON file, or database. This allows for easy access and analysis of the data.
Benefits of Web Scraping
Web scraping offers numerous benefits for businesses and individuals alike. It allows for:
- Data Collection: Gathering data from multiple sources can be time-consuming and labor-intensive. Web scraping automates this process, saving time and resources.
- Competitive Intelligence: Tracking competitor prices, product offerings, and marketing strategies is crucial for business success. Web scraping facilitates this analysis.
- Market Research: Web scraping can be used to gather market data, such as user reviews, product trends, and industry statistics.
- Price Comparisons: Scraping e-commerce websites can provide real-time price comparisons, helping consumers make informed purchasing decisions.
Ethical Considerations
While web scraping is a valuable tool, it's important to use it responsibly and ethically. Respecting website owners' terms of service and avoiding excessive scraping are essential to avoid legal issues or damage to website performance.Tools available for Web Scrapping
Web Scraping can be performed manually, but this can be very time-consuming, especially for data-intensive web pages. This is why automated Web Scraping has become a common technique for extracting large-scale data quickly and efficiently. In addition, there are sevral tools available for this:- browser extensions such as Simple Scraper or Web Scraper, which install directly in your browser.
- no-code software such as octoparse, which lets you create Web Scraping bots without writing any code.
- APIs (Application Programming Interfaces) to access specific data on a website in a more structured and organized way.
- Python libraries to retrieve information using customized scripts over which you have complete control.
However, even if the tools are diverse, the objective remains strictly the same. In this module, we'll be focusing on learning how to Web Scrap using Python libraries.
Main python libraries for Web Scrapping
Python offers several libraries for harvesting information from Web resources. Here are the three most commonly used solutions:
- BeautifulSoup: Quick and easy to learn, BeautifulSoup is the ideal library for getting started with Web Scraping. It may be slower than other libraries for more advanced use cases.
- Scrapy: The Scrapy library enables you to scrape large-scale data, as well as exporting scraped data to various formats such as JSON or CSV. However, its learning curve is steeper than BeautifulSoup. Finally, Scrapy requires a more complex and advanced configuration for the most advanced use cases, so it's harder to get to grips with.
- Selenium: Selenium is first and foremost a library designed for automated web testing. Because of its compatibility with JavaScript, it is also used for web scraping and, unlike the two previous libraries, enables dynamic scraping. Selenium can simulate human behavior to avoid detection by web sites. It's a highly efficient and fast tool that performs more or less as well as Scrapy. However, Selenium can be slower than other libraries for the simplest use cases and is more difficult to use than other libraries for Python beginners. Finally, more and more sites are detecting the use of Selenium and blocking its use.
BeautifulSoup is recommended for beginners to web scraping, Scrapy is recommended for large-scale projects and Selenium is recommended for scraping dynamic web pages with JavaScript. Your choice
of library will therefore depend on your use case and your level of Python skills. Javascript
Javascript is a programming language commonly used to create interactive and dynamic websites, for example, with animations.
As with CSS code, Javascript can be directly included in the header of an HTML document with tags, but does not
appear directly in HTML tags. As the BeautifulSoup library only retrieves the content of the HTML code, we won't be able to retrieve the
information contained in this Javascript code when we scrape a site with BeautifulSoup
How do I retrieve the source code of a web page? ?
In order to achieve our ultimate goal of web scraping, we first need to retrieve the source code of a web page made up of the languages described above.- Inspecting the page with the browser: Command (or Control for Windows) + Shift + C
- Inspect the page with the Requests library: HTTP (Hypertext Transfer Protocol) requests are the web's primary means of communication. Every time we browse a web page, our web browser (the client) asks a web server to retrieve a resource (such as a web page, image or file) so that it can be displayed on our screen.
 Depending on the type of request, there are different methods for instructing the server to perform the desired action and display the requested resource. Below are three examples of methods used by the HTTP protocol:
Depending on the type of request, there are different methods for instructing the server to perform the desired action and display the requested resource. Below are three examples of methods used by the HTTP protocol:
- GET: Read the contents of a resource using its URL
- POST: Send data to the server.
- PUT: Create/replace the content of a resource.
- HEAD: Request only information about the resource, not the resource itself.
Once the web server receives the HTTP request, it processes the request and returns an HTTP response. We'll use the Python requests library to send HTTP requests to web pages. We'll need to fill in the web page link to scrape the page content.
Web-Scraping in python using Beautofulsoup
Web scraping in Python can be achieved using a combination of two popular libraries:requests: is a library for making HTTP requests to websites. It allows you to get the HTML content of a web page, which is the raw data that web scrapers need to work with.Beautiful Soup: is a library for parsing HTML. It provides a clean and easy-to-use interface for extracting the data you want from the HTML content.
The limits of Web Scraping with BeautifulSoup
While BeautifulSoup librariey can be a very effective way of obtaining data in bulk, there are some limitations to Web Scraping that we need to be aware of, and which can make our task more difficult.
The limits of Web Scrapping with BeautifulSoup:
- Dynamic content:
BeautifulSoupis a perfect library for getting started with Web Scraping, but it doesn't allow you to harvest information from all websites. Indeed, some web pages are constructed in complex ways, which can make data extraction difficult. For example, websites that use technologies such as Javascript to make their content dynamic can be difficult, if not impossible, to scrape withBeautifulSoup, as this library is based solely on the initial source code of the page, whereas dynamic content is, by definition, elements that can change or appear after the initial page load, in response to user actions such as button clicks or scrolling.If the page we want to scrape contains dynamic content, we need to use more advanced tools that are capable of interacting with this dynamic content. The
Seleniumlibrary, for example, is a possible solution, as it can simulate user actions to load dynamic content and extract the necessary data. - Data reliability:
Reliability is a major limitation of Web Scraping, as Web pages can be updated regularly, which can lead to errors in the structure of the HTML code and missing or incorrect data in the scraping. When a Web page is modified, HTML tags can change, class names can be modified, elements can be moved, etc. This can lead to incorrect data being collected. This can lead to the collection of incorrect or missing data and errors in scraping. For example, if we are scraping a website to obtain pricing data for a product, a change in the structure of the website may mean that the data is no longer collected correctly and may result in an error in our script.
To overcome this limitation, we can use advanced monitoring techniques to track changes to web pages. In this way, we can quickly detect errors and correct them. In practice, this involves setting up Python monitoring scripts to detect changes in the structure of the web page and alert the developers in the event of a problem. These scripts detect errors by defining a set of validation rules, which check whether the data collected is correct and consistent. For example, validation rules can check whether the prices collected fall within a certain price range, whether they are higher than the previous price, or whether there has been a significant price increase or decrease. Validation rules can also check for missing or non-compliant data, and report errors to the user.
On a more general level, we can also compare the entire content of a page with an earlier version by hashing these pages, i.e., by obtaining the unique fingerprint of a file through complex mathematical calculations that form a function, known as a hash function, obtained using the hashlib library. In this way, we can check the version of the web page by comparing the current hash with the previously stored hash. If the two hashes are identical, this means that the website has not been modified since the last time you scanned it. If the two hashes are different, it means that the website has been modified and that you need to correct your scraping script.
By using these techniques, we can improve the reliability of our scraping script and ensure that the data collected is accurate, valid and compliant.
- Legal aspects of Web scraping:

The legality of web scraping is a complex issue with no easy answer. It depends on a variety of factors, including the purpose of the scraping, the website's terms of service, and the laws of the country where the website is located.
n general, web scraping is legal if it is done for a non-commercial purpose and does not cause the website to slow down or crash. However, if you are scraping data for a commercial purpose, you may need to obtain the website owner's permission. You should also be careful not to scrape data that is copyrighted or that is protected by trade secrets.
Conclusion
Web scraping is a powerful tool that can transform the way we collect, analyze, and utilize data from the vast digital landscape. By employing ethical practices and using appropriate tools, we can harness the power of web scraping to enhance our businesses, inform our decisions, and drive innovation.