
Machine learning: Unsupervised Learning
Introduction
Unsupervised learning is a branch of machine learning where the model learns from unlabeled data. Unlike supervised learning, it does not require labeled inputs or outputs. Instead, it focuses on discovering hidden patterns, groupings, or structures within the data. It’s especially useful in exploratory data analysis, clustering, anomaly detection, and dimensionality reduction.
Core Idea
In unsupervised learning:
- There are no target labels (no $y$)
- Groups or clusters of similar data points
- Dimensionality reduction or feature compression
- Density or distribution estimates
- Anomalies or outliers
Key components often include:
- Input: Unlabeled dataset (X)
- Goal: Find hidden patterns or reduce complexity
- Output: Groups, compressed representations, or flagged outliers
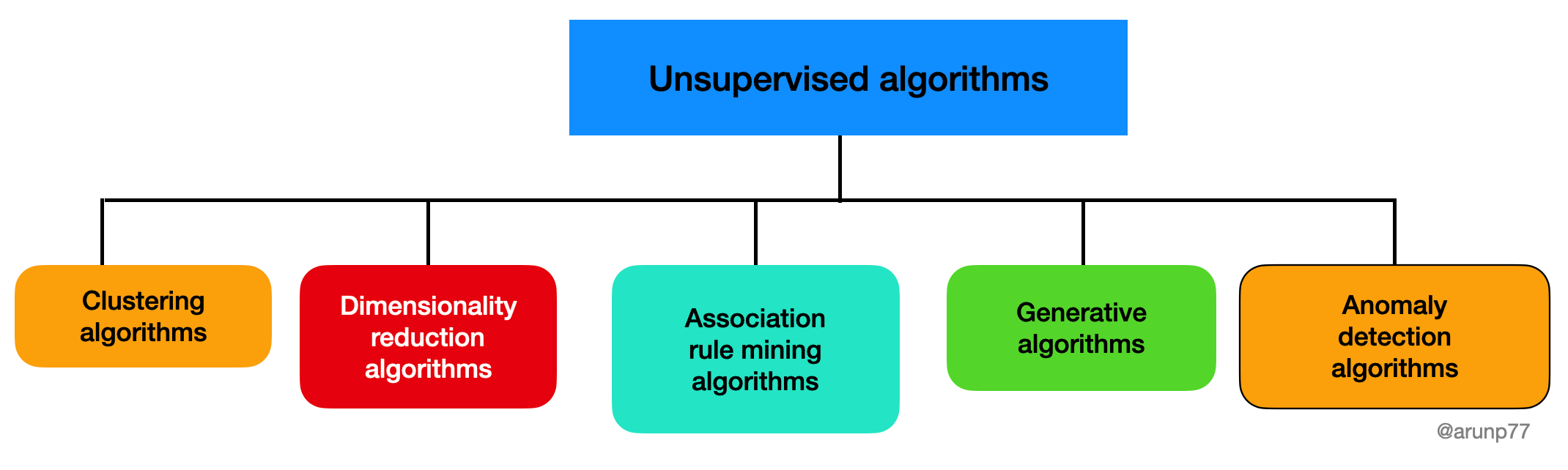
Key Types of Unsupervised Algorithms
1. Clustering Algorithms
- K-Means: Partitions data into
Kgroups by minimizing intra-cluster distances. Fast and scalable. - Hierarchical Clustering: Creates a nested tree of clusters using a bottom-up (agglomerative) or top-down approach. Doesn’t require K.
- DBSCAN: Groups densely packed points. Great for detecting noise and arbitrary shapes.
- Gaussian Mixture Models (GMM): Soft clustering using a probabilistic approach with Gaussian distributions.
2. Dimensionality Reduction
- PCA: Projects data into a lower-dimensional space while preserving variance.
- t-SNE: Non-linear technique for 2D/3D visualization by preserving local relationships.
- UMAP: Similar to t-SNE but faster and better at preserving global structure.
3. Anomaly Detection
- One-Class SVM: Learns a decision boundary around the normal data points.
- Isolation Forest: Randomly splits data—anomalies are isolated faster with fewer splits.
- Local Outlier Factor (LOF): Detects outliers by comparing local density to neighbors.
4. Association Rule Learning
- Apriori Algorithm: Finds frequent itemsets and derives association rules (e.g., market basket analysis).
- Eclat Algorithm: A vertical layout-based alternative to Apriori, faster for large datasets.
Use Cases
| Task | Common Algorithm |
|---|---|
| Customer Segmentation | K-Means, GMM |
| Document Topic Modeling | LDA (Latent Dirichlet Allocation) |
| Anomaly Detection in Logs | Isolation Forest, LOF |
| Recommender Systems | Association Rules (Apriori, Eclat) |
| High-Dimensional Data Visualization | t-SNE, UMAP, PCA |
References
- My github Repositories on Remote sensing Machine learning
Some other interesting things to know:
- Visit my website on For Data, Big Data, Data-modeling, Datawarehouse, SQL, cloud-compute.
- Visit my website on Data engineering