
Big data processing with Pyspark DataFrames
RDD's - Resilient Distributed Datasets
The RDD structure is the elementary structure of Spark. It is flexible and optimal in performance for any linear operation. However, this structure has limited performance when it comes to non-linear operations, which is why we will introduce the DataFrame structure in the following exercise.
A good reference for the pyspark can be found at Link. Another link with some
good examples can be found at Link.
Example
Let's do a example here. First we will create a Sparkcontext via sparksession and then load a datafile and in the end do some Machine learning analysis.- Step-1: Build the SparkSession
# Importing Spark Session and SparkContext
from pyspark.sql import SparkSession
from pyspark import SparkContext
# Definition of a SparkContext
SparkContext.getOrCreate()
# Definition of a SparkSession
spark = SparkSession \
.builder \
.master("local") \
.appName("Introduction to DataFrame") \
.getOrCreate()
spark
# Creating a shortcut to the SparkContext already created
sc = SparkContext.getOrCreate()
sc
rdd_row will also be created using the map, applying on each line the structure Row with the explanatory variables year, month, day and flightNum.
The data file is available at Github repo.
# Importing Row from the pyspark.sql package
from pyspark.sql import Row
# Loading the file '2008_raw.csv'
rdd = sc.textFile('2008_raw.csv').map(lambda line: line.split(","))
# Creating a new rdd by selecting the explanatory variables
rdd_row = rdd.map(lambda line: Row(year = line[0],
month = line[1],
day = line[2],
flightNum = line[5]))
# Creating a data frame from an rdd
df = spark.createDataFrame(rdd_row)
df.show(5) # to show the top 5 rows.
raw_df = spark.read.csv('2008.csv', header=True)raw_df.printSchema()flights1 dataframe, containing only the variables: 'year', 'month', 'day', 'flightNum', 'origin', 'dest', 'distance', 'canceled', 'cancellationCode'. and then displaying the first 20 lines:
# Creating a data frame containing only the explanatory variables
flights1 = raw_df.select('year', 'month', 'day', 'flightNum', 'origin', 'dest', 'distance', 'canceled', 'cancellationCode', 'carrierDelay')
# Display of 20 first lines
flights1.show() # 'show' displays 20 lines by default
flights = raw_df.select(raw_df.year.cast("int"),
raw_df.month.cast("int"),
raw_df.day.cast("int"),
raw_df.flightNum.cast("int"),
raw_df.origin.cast("string"),
raw_df.dest.cast("string"),
raw_df.distance.cast("int"),
raw_df.canceled.cast("boolean"),
raw_df.cancellationCode.cast("string"),
raw_df.carrierDelay.cast("int"))
# Display of 20 first lines
flights.show()
flights.select('flightNum').distinct().count()describe to obtain a summary of the dataframe.
flights.describe().toPandas()A groupby just like python can be used to do some more analysis.
flights.groupBy('cancellationCode', 'canceled').count().show()A filter can be used to select certain rows based on conditions.
flights.filter(flights.cancellationCode == 'C').show()The withColumn methods allows us to create a new column.
flights.withColumn('isLongFlight', flights.distance > 1000 ).show(10)isLongFlight that will be true if the flight is more than 1000 miles long and then displays first 10 line.
dropna or fillna, as in module Pandas. df.fillna( newValue, 'columnName') flights.fillna(0, 'carrierDelay').show(6)To replace a value with some other value, we can use df.replace(oldValue, newValue). To replace on a specific column, we can use df.replace(oldValue, newValue, 'columnName'
To replace sevral values to be replaced: df.replace([oldValue1, oldValue2], [newValue1, newValue2], 'columnName')
df.orderBy(df.age) or df.orderBy(df.age.desc())
to order the dataframe on the basis of variable age in a decreasing order.flights.orderBy(flights.flightNum.desc()).show()createOrReplaceTempView.
# Creating an SQL view
flights.createOrReplaceTempView("flightsView")
# Creating a data frame containing only the variable "carrierDelay"
sqlDF = spark.sql("SELECT carrierDelay FROM flightsView")
# Display of the first 10 lines
sqlDF.show(10)
flightsView and then we create a DataFrame called sqlDF containing only the carrierDelay variable using a sql query. In the end we display the first line.
withRemplacement: a Boolean to specifyFalseif you don't want to overwrite the DataFramefraction: the fraction of data to be keptseed: an integer that allows the results to be reproduced: for the same seed, a function, although random, will always give the same results
flights.sample(False, .0001, seed = 222).toPandas()
This display around ten lines of the database in an elegant way (just like pandas dataframe).
Machine learning with Pyspark Regression with PySpark
Spark ML is a very recent module, developed in parallel by Databricks and UC Berkeley AMPLab and launched at the end of 2015. Spark ML allows to run the majority of the algorithms of Machine Learning in a distributed way with a very big gain in performance. In this part, we will study the case of a simple regression in order to understand how to prepare the data and deal with a Machine Learning problem using Spark ML. More advanced algorithms are the objective of the following exercise. Let's break this again:- Run the cell below to build a SparkSession for our exercise.
# Importing SparkSession and SparkContext
from pyspark.sql import SparkSession
from pyspark import SparkContext
# Defining a SparkContext locally
sc = SparkContext.getOrCreate()
# Building a Spark Session
spark = SparkSession \
.builder \
.appName("Introduction to Spark ML") \
.getOrCreate()
spark
- A variable containing the year of the song
- 12 variables containing a 12-dimensional projection of the song's audio timbre
- 78 variables containing audio timbre covariance information
YearPredictionMSD.txt into a dataframe df_raw.
df_raw = spark.read.csv('YearPredictionMSD.txt')
# First display method
df_raw.show(2, truncate = 4)
# By modifying the values of 'truncate', this method does not allow a good visualization of the data
# by the number of variables
# Second display method
df_raw.sample(False, .00001, seed = 222).toPandas()
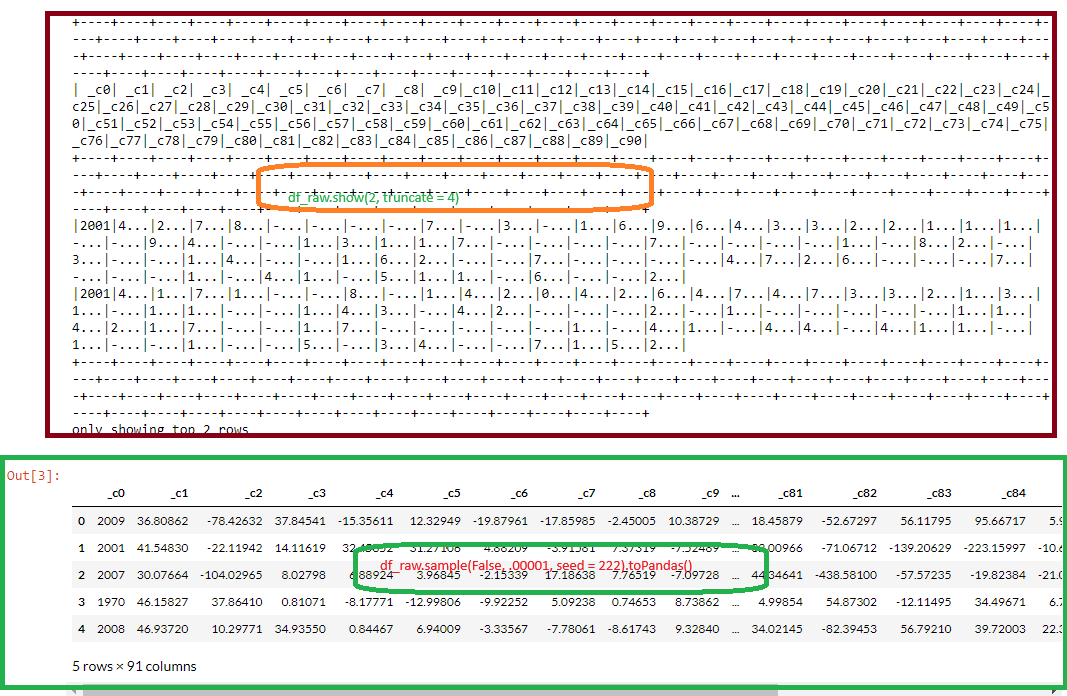
Displaying a database with the method
show() is faster. However, the result can sometimes be incomprehensible when there are too many variables.
We can then select a few variables and truncate the display to make them clean or privilege the succession of methods sample() and toPandas()
taking care to choose a reasonable number of lines to display. It should be kept in mind that even if the sample method is relatively fast, it necessarily involves a
counting of lines, a simple but slow operation in Spark. The DataSchema can be checked using df_raw.printSchema(). To change the type of each variable, it would be necessary to change its type as follows :
df_raw.select(df_raw._c0.cast("double"),
df_raw._c1.cast("double"),
df_raw._c2.cast("double"),
df_raw._c3.cast("double"),
...
)
col function from the sub-module pyspark.sql.functions.
The col function allows you to directly name a column and automate this type of approach within a loop. The next two rows then allow you to change all the columns to dual' in a new DataFrame df:
exprs = [col(c).cast("double") for c in df_raw.columns]
df = df_raw.select(*exprs)
df from df_raw by changing the types of columns related to the timbre to double and the year to int.
from pyspark.sql.functions import col
# Convert columns related to timbre to double and year to int
exprs = [col(c).cast("double") for c in df_raw.columns[1:91]]
df = df_raw.select(df_raw._c0.cast('int'), *exprs)
# display of the variable schema
df.printSchema()

df using df.describe().toPandas().
svmlib format: To be used by the Machine Learning algorithms of Spark ML, the database must be a DataFrame containing 2 columns:
label: containing the variable to be predictedfeatures: containing the explanatory variables.
DenseVector() function, from the package pyspark.ml.linalg, allows you to group several variables into one.
Note: To be able to use the function
DenseVector, we have to use the method map after transforming the DataFrame to rdd.
rdd_ml = df.rdd.map(lambda x: (x[0],
DenseVector(x[1:])))
# assuming that the variable to be explained is
# in the first position
df_ml = spark.createDataFrame(rdd_ml, ['label', 'features'])
DenseVector, then create rdd_ml separating the variable to be explained from the features (to be put in the form DenseVector). df_ml is created containing the database under the two variables: 'labels' and 'features'.
from pyspark.ml.linalg import DenseVector
# Creating an rdd by separating the variable to be explained from the features
rdd_ml = df.rdd.map(lambda x: (x[0], DenseVector(x[1:])))
# Creation of a data frame composed of two variables: label and features
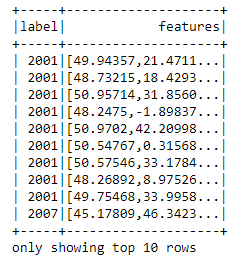
df_ml = spark.createDataFrame(rdd_ml, ['label', 'features'])
# Display of the first 10 lines of the data frame
df_ml.show(10)
train, test = df.randomSplit([.7, .3], seed= 222).train, test = df_ml.randomSplit([.8, .2], seed= 1234)LinearRegression
in the module pyspark.ml.regression. This function allows you to perform a regression in a distributed way and performs calculations on the different clusters predefined in the SparkSession,
regardless of their number or the size of the database. To use it, we must proceed with the two usual steps:
- Create the function with context-specific parameters,
- Use the
fitmethod to apply it to the data.
For more details on this method, we can go to following link.
We now import the LinearRegression, create a distributed linear regression function lr to be applied to the set train. We then create linearModel,
the model from lr applied to train.
from pyspark.ml.regression import LinearRegression
# Creating a linear regression function
lr = LinearRegression(labelCol='label', featuresCol= 'features')
# Fitting of training data "train".
linearModel = lr.fit(train)
transform() method to make predictions using only the test set as an argument.
predicted = linearModel.transform(test)
# Printing prediction
predicted.show()
linearModel.summary.
print("RMSE:", linearModel.summary.rootMeanSquaredError)
print("R2: ", linearModel.summary.r2)
RMSE: 9.548411838648486
R2: 0.2363424607632092
from pprint import pprint
pprint(linearModel.coefficients)
DenseVector([0.876, -0.0562, -0.0439, 0.0036, -0.0149, -0.2193, -0.0071, -0.0997, -0.0705, 0.0263, -0.1676, -0.0002, 0.0466, 0.0004, -0.0004, 0.0006, 0.0005, 0.0014, 0.002, 0.0021, 0.0007, -0.0001, 0.0074, 0.0029, -0.0036, 0.0001, 0.0016, 0.0005, 0.001, -0.0003, -0.0013, -0.0015, -0.0054, 0.0026, 0.0017, -0.0052, -0.0003, 0.0007, 0.0014, -0.0016, -0.0019, -0.0008, -0.0014, -0.0024, -0.0033, 0.0067, 0.0005, -0.0021, 0.0003, 0.0019, 0.0002, -0.0016, 0.0019, 0.0004, -0.0, 0.0002, -0.002, 0.0019, -0.0013, 0.0002, -0.0031, -0.002, -0.0075, 0.0012, -0.0021, 0.0006, -0.0001, -0.0004, -0.0043, -0.0052, -0.0011, 0.0002, 0.0007, 0.004, 0.0028, 0.0156, 0.0002, -0.0044, -0.0002, -0.0002, -0.0002, -0.0005, 0.0013, 0.0011, 0.0257, 0.0002, 0.0011, -0.0309, -0.0014, -0.0014])
Spark provides other Machine learning algorithms like Classification, Clustering etc., but for simplicity let's go with Regression. SOme of the important function that are being developed for the spark as follows:
LinearRegression(): to perform a linear regression when the label is supposed to follow a normal distributionGeneralizedLinearRegression(): to perform a generalized linear regression when the label is supposed to follow another law specified in the parameter family (gaussian, binomial, poisson, gamma)AFTSurvivalRegression(): to perform a survival analysis.DecisionTreeRegressor(): for a decision treeRandomForestRegressor(): for a random forest of decision treesGBTRegressor(): for a forest of gradient-boosted trees.
References
- Official Documentation
- Databricks Learning Academy
- Spark by Examples
- Datacamp tutorial.
- For databricks, you can look at tutorial videos on youtube at youtube video by Bryan Cafferky, writer of the book "Master Azure Databricks". A great playlist for someone who just want to learn about the big data analytics at Databricks Azure cloud platform.
- See the video for pyspark basics by Krish Naik. Great video for starter.
- Great youtube on Apache spark one premise working.
Some other interesting things to know:
- Visit my website on For Data, Big Data, Data-modeling, Datawarehouse, SQL, cloud-compute.
- Visit my website on Data engineering