
Natural Language Processing

Introduction
Natural Language Processing (NLP) is a fascinating field at the intersection of linguistics, computer science, and artificial intelligence (AI). NLP is the ability of a computer program to understand human language as it's spoken and written -- referred to as natural language. It uses machine learning to enable computers to understand and communicate with human language.NLP research has enabled the era of generative AI, from the communication skills of large language models (LLMs) to the ability of image generation models to understand requests. NLP is already part of everyday life for many, powering search engines, prompting chatbots for customer service with spoken commands, voice-operated GPS systems and digital assistants on smartphones.
What is NLP?
NLP is a branch of AI that deals with the interaction between computers and humans using natural language. The ultimate goal of NLP is to read, decipher, understand, and make sense of the human languages in a manner that is valuable.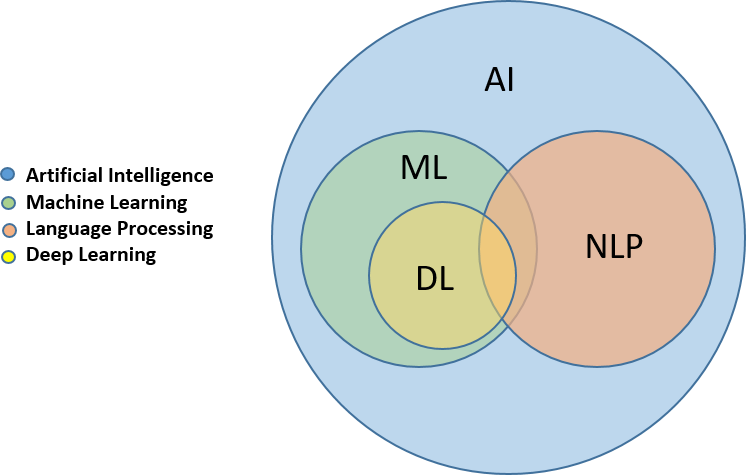
Applications of NLP
NLP has a wide range of applications, including but not limited to:- Chatbots and Virtual Assistants: Powering conversational agents like Siri, Alexa, and Google Assistant.
- Text Analytics: Analyzing customer feedback, reviews, and social media posts.
- Language Translation: Translating documents and websites into multiple languages.
- Speech Recognition: Converting spoken language into text.
- Content Recommendation: Suggesting relevant articles, videos, or products based on user behavior.
Getting Started with NLP
One can follow following steps:- Learn the basics of machine learning and deep learning: Python is the most popular language for NLP due to its simplicity and extensive library support. Familiarize yourself with Python basics before diving into NLP.
- Choose a programming language and framework for NLP development: Text preprocessing involves cleaning and preparing text data for analysis. Common steps include:
- Removing Punctuation: Stripping punctuation marks from text.
- Lowercasing: Converting all text to lowercase to ensure uniformity.
- Removing Stop Words: Filtering out common words like "and," "the," and "is" that do not carry significant meaning.
- Stemming and Lemmatization: Reducing words to their root form. For example, "running" becomes "run."
- Explore NLP Libraries: Several Python libraries make NLP tasks easier:
- NLTK (Natural Language Toolkit): A comprehensive library for various NLP tasks.
- spaCy: An efficient and user-friendly library for advanced NLP.
- TextBlob: Simplifies text processing tasks like noun phrase extraction and sentiment analysis.
- Transformers (by Hugging Face): Provides state-of-the-art pre-trained models for various NLP tasks.
- Build Simple NLP Projects: Start with small projects to apply what you’ve learned:
- Sentiment Analysis: Analyze the sentiment of movie reviews.
- Chatbot: Create a simple rule-based chatbot.
- Text Summarization: Summarize news articles.
- Dive into Advanced Topics: Once you’re comfortable with the basics, explore advanced topics like:
- Word Embeddings: Represent words as vectors in a continuous vector space.
- Recurrent Neural Networks (RNNs): Handle sequential data for tasks like language modeling and machine translation.
- Transformers: Use models like BERT and GPT for state-of-the-art performance in various NLP tasks.
How does natural language processing work?
NLP uses many different techniques to enable computers to understand natural language as humans do. Whether the language is spoken or written, natural language processing can use AI to take real-world input, process it and make sense of it in a way a computer can understand. Just as humans have different sensors -- such as ears to hear and eyes to see -- computers have programs to read and microphones to collect audio. And just as humans have a brain to process that input, computers have a program to process their respective inputs. At some point in processing, the input is converted to code that the computer can understand.Main phases of NLP:
There are two main phases to natural language processing (for reference, please see the link):- Data preprocessing: Data preprocessing involves preparing and cleaning text data so that machines can analyze it. Preprocessing puts data in a workable form and highlights features in the text that an algorithm can work with. There are several ways this can be done, including the following:
- Tokenization: Tokenization substitutes sensitive information with nonsensitive information, or a token. Tokenization is often used in payment transactions to protect credit card data.
- Stop word removal: Common words are removed from the text, so unique words that offer the most information about the text remain.
- Lemmatization and stemming: Lemmatization groups together different inflected versions of the same word. For example, the word "walking" would be reduced to its root form, or stem, "walk" to process.
- Part-of-speech tagging: Words are tagged based on which part of speech they correspond to -- such as nouns, verbs or adjectives
- Algorithm development: Once the data has been preprocessed, an algorithm is developed to process it.
Algorithms
There are many different natural language processing algorithms, but the following two main types are commonly used:- Rule-based system - The early days: The earliest applications of Natural Language Processing (NLP) were built using simple if-then decision trees that relied on preprogrammed rules. These systems could only provide answers to specific prompts, such as the original version of Moviefone. Without any machine learning or AI capabilities, rule-based NLP was highly limited and lacked scalability.
- Machine learning-based system: Machine learning algorithms use statistical methods. They learn to perform tasks based on training data they're fed and adjust their methods as more data is processed. Using a combination of machine learning, deep learning and neural networks, natural language processing algorithms hone their own rules through repeated processing and learning.
- The Emergence of Statistical NLP: Developed later, statistical NLP automates the extraction, classification, and labeling of elements in text and voice data. It assigns a statistical likelihood to each possible meaning of those elements using machine learning. This enables a sophisticated analysis of linguistic features such as part-of-speech tagging.
Statistical NLP introduced the essential technique of mapping language elements—such as words and grammatical rules—to vector representations. This allows language to be modeled using mathematical methods, including regression and Markov models. These advancements informed early NLP applications such as spellcheckers and T9 texting (Text on 9 keys, used on Touch-Tone telephones).
- The Rise of Deep Learning-Based NLP: Recently, deep learning models have become the dominant approach in NLP, leveraging vast amounts of raw, unstructured data—both text and voice—to achieve unprecedented accuracy. Deep learning represents an evolution of statistical NLP, distinguished by its use of neural network models. There are several subcategories of these models:
- Sequence-to-Sequence (seq2seq) Models: Based on recurrent neural networks (RNNs), seq2seq models have primarily been used for machine translation. They convert a phrase from one language (such as German) into a phrase in another language (such as English).
- Transformer Models: Transformer models tokenize language by considering the position of each token (words or subwords) and employ self-attention mechanisms to capture dependencies and relationships within the text. They can be efficiently trained using self-supervised learning on massive text datasets. A landmark in transformer models is Google’s BERT (Bidirectional Encoder Representations from Transformers), which revolutionized how Google’s search engine operates.
- Autoregressive Models: Autoregressive transformer models are specifically trained to predict the next word in a sequence, significantly advancing text generation capabilities. Examples of autoregressive large language models (LLMs) include GPT, LLaMA, Claude, and the open-source Mistral.
- Foundation Models: Prebuilt and curated foundation models accelerate NLP efforts and enhance operational trust. For example, IBM's Granite™ foundation models are applicable across various industries, supporting tasks like content generation and insight extraction. These models facilitate retrieval-augmented generation, improving response quality by linking to external knowledge sources. They also perform named entity recognition, identifying and extracting key information from text.
- The Emergence of Statistical NLP: Developed later, statistical NLP automates the extraction, classification, and labeling of elements in text and voice data. It assigns a statistical likelihood to each possible meaning of those elements using machine learning. This enables a sophisticated analysis of linguistic features such as part-of-speech tagging.
NLP_Project/
├── README.md
├── Fundamentals/
│ ├── Language_Models/
│ │ ├── Statistical_Language_Models.md
│ │ └── Neural_Language_Models.md
│ ├── Text_Preprocessing/
│ │ ├── Tokenization.md
│ │ ├── Stemming_and_Lemmatization.md
│ │ └── Stop_Word_Removal.md
│ └── Feature_Engineering/
│ ├── Bag_of_Words.md
│ ├── TF_IDF.md
│ └── Word_Embeddings.md
├── Techniques/
│ ├── Classification/
│ │ ├── Naive_Bayes.md
│ │ ├── Logistic_Regression.md
│ │ └── Support_Vector_Machines.md
│ ├── Sequence_Modeling/
│ │ ├── Hidden_Markov_Models.md
│ │ ├── Recurrent_Neural_Networks.md
│ │ └── Transformers.md
│ └── Generation/
│ ├── Language_Modeling.md
│ ├── Text-Summarization.md
│ └── Machine_Translation.md
├── Applications/
│ ├── Text_Classification/
│ │ ├── Sentiment_Analysis.md
│ │ ├── Topic_Modeling.md
│ │ └── Spam_Detection.md
│ ├── Information_Extraction/
│ │ ├── Named_Entity_Recognition.md
│ │ ├── Relation_Extraction.md
│ │ └── Event_Extraction.md
│ └── Conversational_AI/
│ ├── Chatbots.md
│ ├── Virtual_Assistants.md
│ └── Dialog_Systems.md
├── Evaluation/
│ ├── Intrinsic_Evaluation/
│ │ ├── Perplexity.md
│ │ ├── BLEU_Score.md
│ │ └── F1_Score.md
│ └── Extrinsic_Evaluation/
│ ├── Task_specific_Metrics.md
│ └── Human_Evaluation.md
├── Challenges/
│ ├── Data_Sparsity.md
│ ├── Ambiguity.md
│ ├── Contextual_Understanding.md
│ └── Commonsense_Reasoning.md
├── Tools_and_Frameworks/
│ ├── Programming_Languages/
│ │ ├── Python.md
│ │ ├── Java.md
│ │ └── C++.md
│ └── Libraries_and_Frameworks/
│ ├── NLTK.md
│ ├── spaCy.md
│ ├── Hugging_Face_Transformers.md
│ ├── TensorFlow.md
│ └── PyTorch.md
└── Research_Directions/
├── Multilingual_NLP.md
├── Multimodal_NLP.md
├── Ethical_and_Responsible_NLP.md
└── Few_shot_and_Zero_shot_Learning.md
References
- My Github repo with all codes.
- What is NLP (natural language processing)? (IBM) Contributor: Jim Holdsworth).
- What are large language models (LLMs)? (IBM)
- What is generative AI?(IBM), Contributor: Cole Stryker, Mark Scapicchio
- Udemy Bootcamp on Machine learning, Deep Learning and NLP, by Krish Naik
Some other interesting things to know:
- Visit my website on For Data, Big Data, Data-modeling, Datawarehouse, SQL, cloud-compute.
- Visit my website on Data engineering