
Scala Spark

Introduction to Kafka
Apache Kafka is an open-source distributed event streaming platform initially developed by LinkedIn in 2011 and later open-sourced as an Apache Software Foundation project. It is designed to handle real-time data feeds, allowing for the building of robust and scalable streaming data pipelines. Kafka is widely used in various industries for applications such as real-time analytics, log aggregation, monitoring, and messaging.
Apache Kafka in Layman Language
Apache Kafka is like a super-efficient postal system for digital messages. Imagine you have a bunch of mailmen (producers) who are constantly picking up messages from people and dropping them into different mailboxes (topics). These mailboxes are organized by subject, so all related messages go into the same mailbox.
Now, there are other mailmen (consumers) who come to these mailboxes and pick up messages to deliver to the right people or systems. Kafka makes sure this process is fast, reliable, and can handle a huge number of messages without getting overwhelmed.
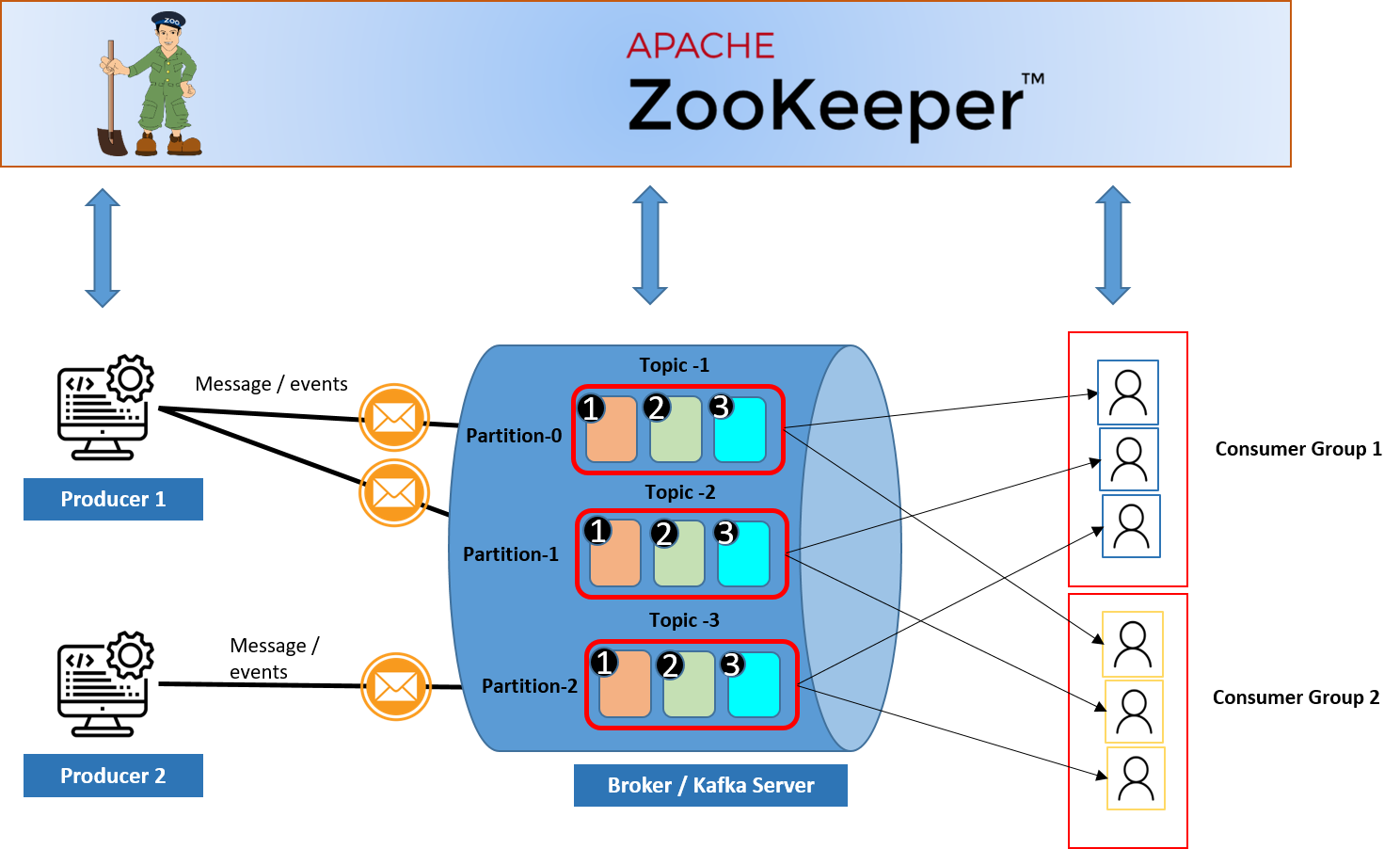
In short, Apache Kafka helps in moving lots of information from one place to another smoothly and quickly.In Kafka, data communication revolves around the concepts of producers, topics, and consumers, which closely align with the pub/sub paradigm.
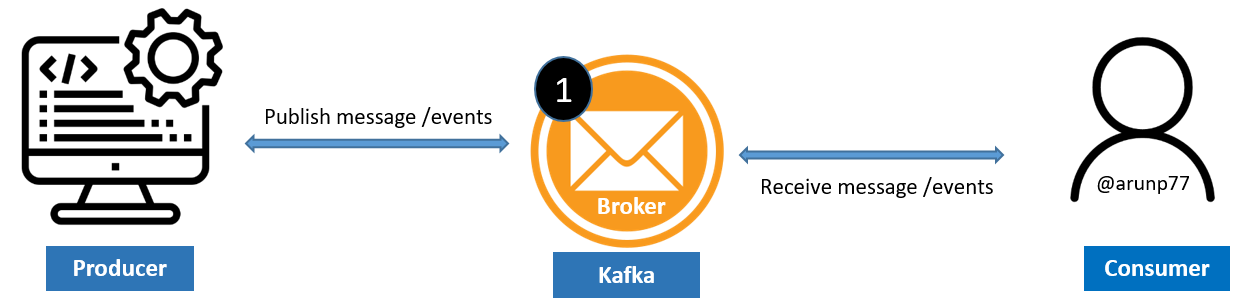
- Producers act as data publishers, generating records and sending them to Kafka topics. These records can represent any type of data, such as log events, sensor readings, or user interactions. Producers are responsible for specifying the topic to which each record should be published.
- Topics serve as logical channels or categories to which records are published. Each topic represents a stream of related data, organized based on a common theme or subject. Topics can have one or more partitions to enable parallel processing and scalability.
- Consumers subscribe to topics of interest and consume messages from them. They read records from the partitions of the subscribed topics and process them according to their application logic. Multiple consumers can subscribe to the same topic, forming consumer groups for parallel processing and load balancing.
In the pub/sub model, a producer produces or push a message to the broker, and broker will store the messages. Consumer will then consume the message from the broker.
Example:
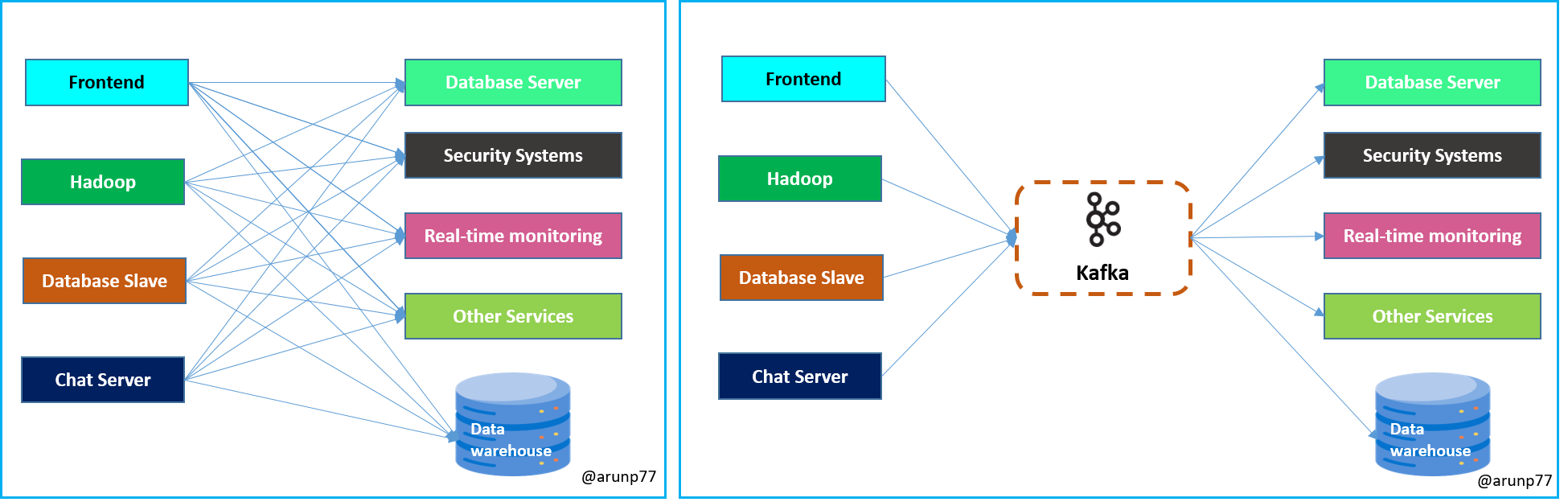
The diagram depicts a scenario where multiple services on the left side (Frontend, Hadoop, Database Slave, Chat Server) are communicating with various services on the right side (Database server, Security Systems, Real-time Monitoring, Other Services, Data Warehouse). Each service on the left side is connected to multiple services on the right side, indicating a complex network of communication channels.
Major issues:
- Point-to-Point Communication: Without Kafka, each service on the left would directly communicate with multiple services on the right (int the first image). This results in a tightly coupled architecture where any change in one service may require changes in multiple other services, leading to complexity and maintenance challenges.
- Scalability: As the number of services increases (represented by 'n' services), the number of communication channels grows exponentially. Managing these point-to-point connections becomes increasingly difficult, leading to scalability issues.
- Fault Tolerance: Point-to-point communication lacks built-in fault tolerance mechanisms. If one service fails or becomes unavailable, it can disrupt the entire communication chain, leading to service outages and data loss.
- Data Loss and Inconsistency: In a direct communication setup, data loss or inconsistency may occur if a service fails to receive or process messages from another service. This can result in data discrepancies and integrity issues.
Kafka Solution: Introducing Kafka as a middleware layer resolves these issues by decoupling communication between services and providing a distributed event streaming platform. The addition of Kafka as an intermediary between the left and right sides of the diagram brings several benefits:
- Message Queuing: Kafka acts as a message queue, allowing services to publish messages (producing) to topics and consume messages (subscribing) from topics asynchronously. This decouples producers and consumers, enabling asynchronous and distributed communication.
- Scalability and Flexibility: Kafka's distributed architecture scales horizontally, allowing for the addition of new producers and consumers without impacting existing services. It provides flexibility in adding or removing services without disrupting the overall communication flow.
- Fault Tolerance and Durability: Kafka replicates data across multiple brokers, ensuring fault tolerance and data durability. If a broker or service fails, Kafka can continue to serve messages from replicated partitions, preventing data loss and maintaining system availability.
- Stream Processing: Kafka supports stream processing capabilities, enabling real-time data processing and analytics on streaming data. Services can consume and process data in real-time, leading to timely insights and actions
- Integration with Ecosystem: Kafka integrates seamlessly with various data processing frameworks and tools, such as Apache Spark, Apache Flink, and Apache Storm, enabling a rich ecosystem of data processing capabilities.
By introducing Kafka as a central messaging backbone, the communication architecture becomes more resilient, scalable, and flexible. It addresses major issues such as point-to-point communication, scalability, fault tolerance, and data consistency, making the overall system more robust and reliable.
Kafka components
Apache Kafka comprises several key components that work together to provide a distributed event streaming platform.
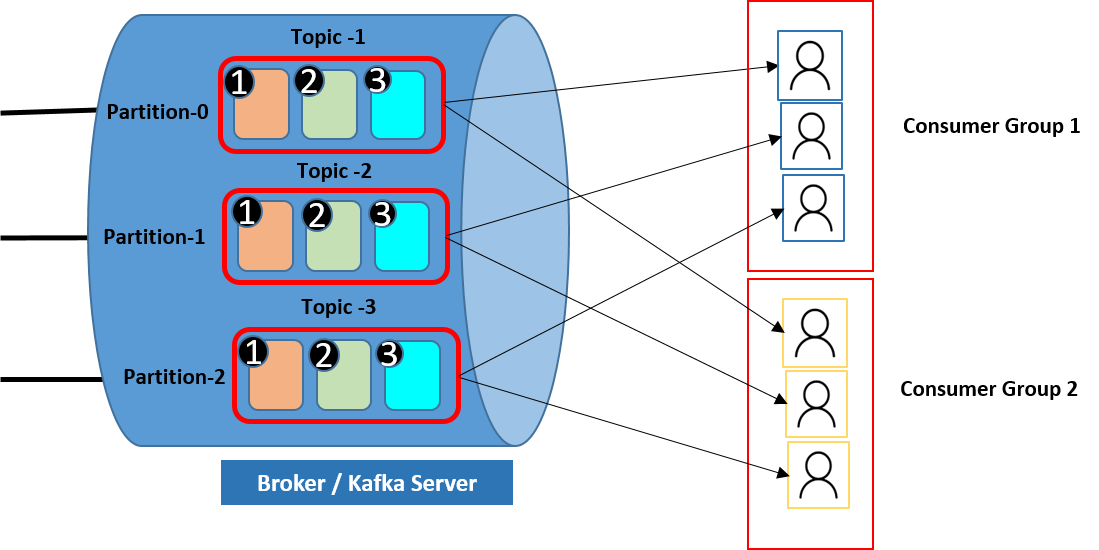
- Publishers (Producers): Producers are responsible for publishing records to Kafka topics. They generate records containing a key, a value, and an optional timestamp and send them to Kafka brokers. Producers can choose the partition to which a record should be sent or rely on Kafka's default partitioning mechanism.
- Consumer: Consumers subscribe to Kafka topics to consume records from them. They read records from partitions in a topic and process them according to their application logic. Consumers can be grouped into consumer groups for parallel processing and load balancing.
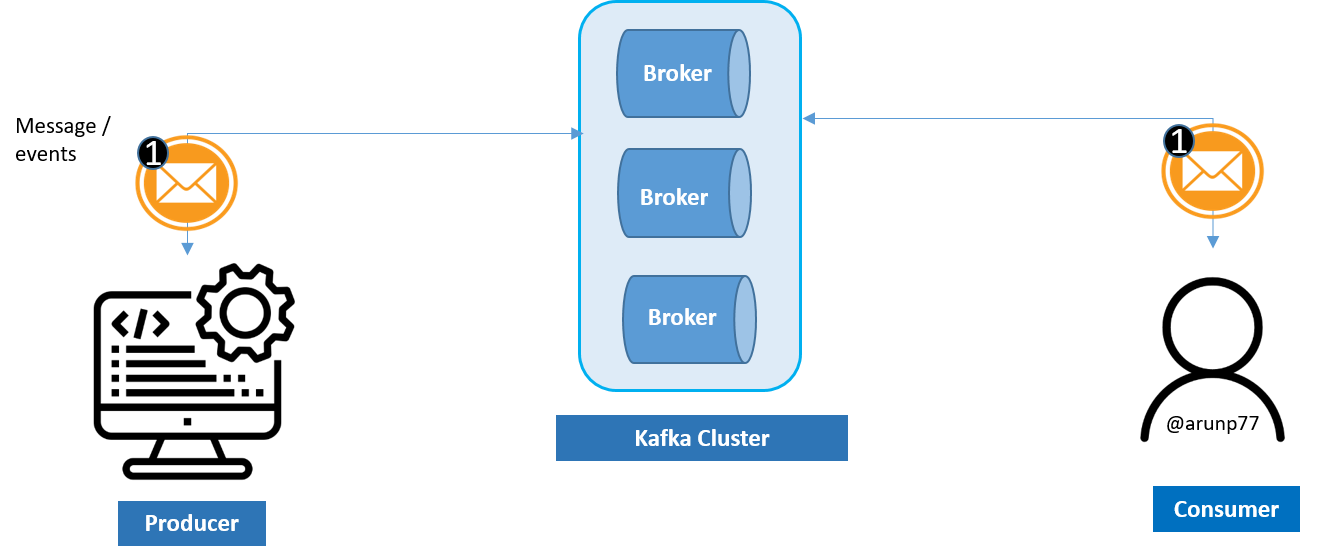
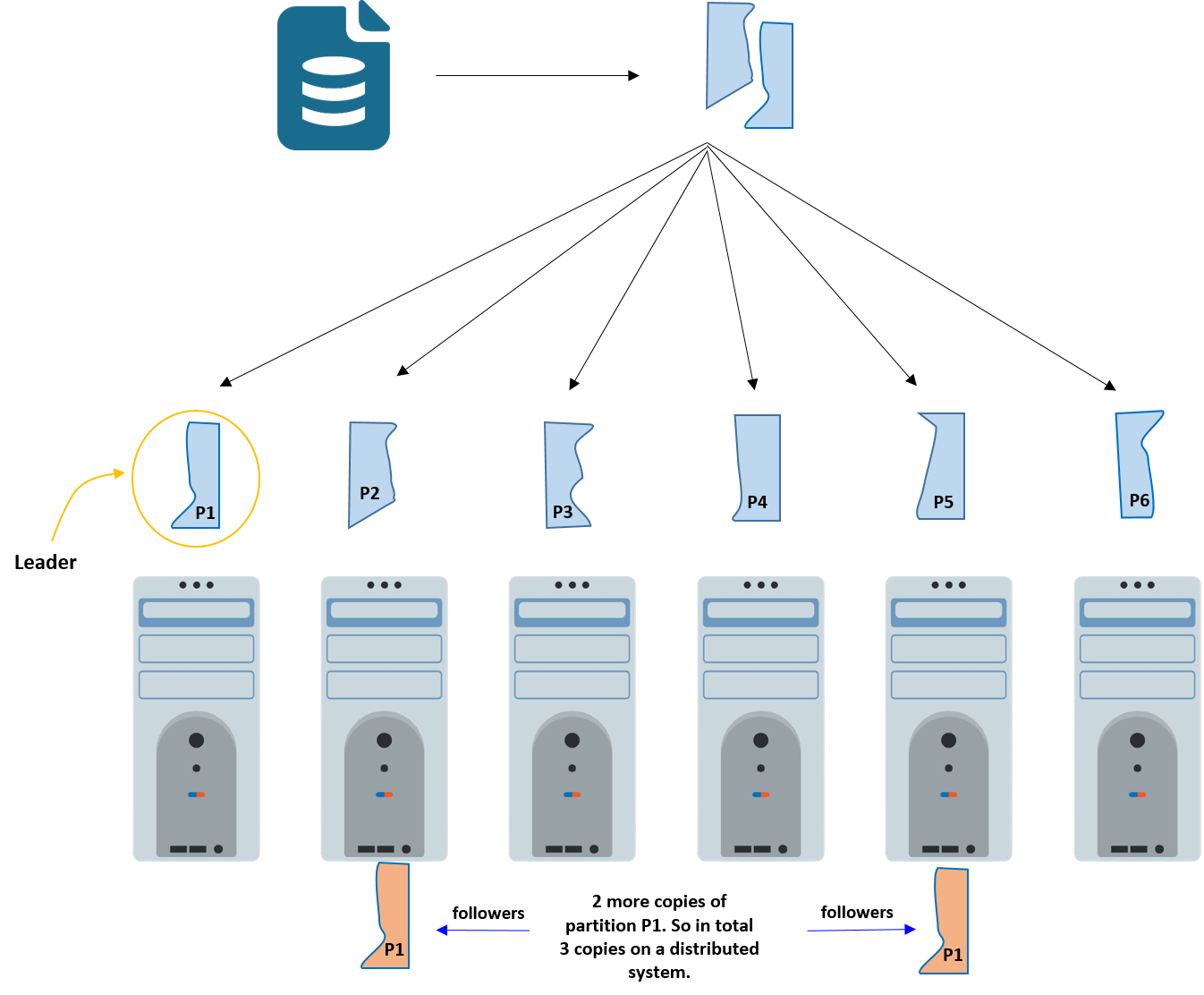
- Broker Kafka brokers are the fundamental building blocks of a Kafka cluster. They handle storage, replication (it means, if replication factor is 3, then we are mentaining 3 copies of the partion), and serving of partitions of topics. Brokers receive messages from producers and deliver them to consumers. Kafka clusters typically consist of multiple brokers distributed across physical or virtual machines.
- Cluster: In Kafka, a cluster refers to a group of Kafka brokers working together to form a distributed messaging system. A Kafka cluster typically consists of multiple brokers, each running on separate physical or virtual machines. These brokers collaborate to store and serve data, handle client requests, and maintain cluster metadata. These are helpful when producer gernate a huge amount of data.
- Topic: Topics represent streams of records, which are organized and categorized based on a common theme or subject. Producers publish records to topics, specifying the topic name to which the record should be sent. Consumers subscribe to topics to consume records from them.
- Partitions: Topics are divided into partitions, which are individual ordered sequences of records. Each partition can be hosted on multiple brokers for fault tolerance and scalability. Partitioning allows Kafka to parallelize data ingestion and consumption, enabling high throughput and efficient data processing.
- Replication factor: In Apache Kafka, topics are divided into partitions to enable parallel processing and scalability. Each partition is a separate log where messages are stored sequentially. Replication factor is the number of copies of a partition that are maintained in the clusters.
- Kafka makes copies of partitions for fault tolerance through replication. Each partition is replicated across multiple Kafka brokers.
- The primary copy of a partition is called the leader, while the others are followers.
- The leader handles all read and write requests, and followers replicate the data from the leader.
- If the leader fails, a follower takes over as the new leader to ensure data availability and durability.
- Offset: In Kafka, an offset represents the position of a consumer within a partition of a topic. It is a numeric value that uniquely identifies a message within the partition. Each message in a partition is assigned a sequential offset, starting from 0 for the first message and increasing incrementally for subsequent messages. Offsets allow consumers to keep track of which messages they have already consumed within a partition. This enables consumers to resume reading from where they left off in case of failures or restarts. Consumers use offsets to determine the next message they need to read from a partition. By maintaining the offset of the last processed message, consumers can retrieve subsequent messages for processing. Consumers can commit their current offset to Kafka to indicate that they have successfully processed messages up to that point. This commit is typically done atomically along with processing logic to ensure exactly-once processing semantics.
- Consumer Group: A consumer group is a logical grouping of consumers that jointly consume and process records from one or more partitions of a topic. Each partition within a topic is consumed by exactly one consumer within a consumer group, enabling parallel processing and load distribution.
- Zookeper: ZooKeeper is used by Kafka for managing cluster metadata, leader election, and synchronization. It maintains information about brokers, topics, partitions, and consumer group membership. While ZooKeeper was a critical component in earlier versions of Kafka, newer versions are gradually moving towards removing this dependency.
Key broker configurations
In Apache Kafka, brokers are critical components that handle message storage, retrieval, and distribution across the cluster. Configuring Kafka brokers properly is essential for performance, scalability, and fault tolerance. Here are some key Kafka broker configurations:- General Settings:
Configuration Description Example broker.id Unique identifier for each broker in the Kafka cluster. It's crucial for differentiating brokers, especially in clusters with multiple brokers. broker.id=1listeners Specifies the network interfaces and ports on which the broker listens for client requests (e.g., producers, consumers). listeners=PLAINTEXT://localhost:9092log.dirs Directories where Kafka stores partition data. Multiple directories can be specified for load balancing across disks. log.dirs=/var/lib/kafka/data - Topic and Log Management:
Configuration Description Example num.partitions Default number of partitions per topic when a new topic is created without specifying the number of partitions. num.partitions=3log.retention.hours Time period for which Kafka retains messages. After this period, messages are eligible for deletion. log.retention.hours=168(7 days)log.segment.bytes Maximum size of a single log segment file. Once this size is reached, Kafka rolls over to a new segment file. log.segment.bytes=1073741824(1 GB)log.cleanup.policy Defines the cleanup policy for logs. Options are delete(removes old logs) andcompact(log compaction for topics with keys).log.cleanup.policy=delete - Replication and Fault Tolerance:
Configuration Description Example num.partitions Default number of partitions per topic when a new topic is created without specifying the number of partitions. num.partitions=3log.retention.hours Time period for which Kafka retains messages. After this period, messages are eligible for deletion. log.retention.hours=168(7 days)log.segment.bytes Maximum size of a single log segment file. Once this size is reached, Kafka rolls over to a new segment file. log.segment.bytes=1073741824(1 GB)log.cleanup.policy Defines the cleanup policy for logs. Options are delete(removes old logs) andcompact(log compaction for topics with keys).log.cleanup.policy=deletedefault.replication.factor Default replication factor for topics when created. Ensures redundancy and fault tolerance. default.replication.factor=3min.insync.replicas Minimum number of in-sync replicas that must acknowledge a write for the write to be considered successful. Helps in ensuring data durability. min.insync.replicas=2unclean.leader.election.enable Determines if Kafka can elect an out-of-sync replica as leader in case of failure. Disabling this ensures data consistency but might reduce availability. unclean.leader.election.enable=false - Performance Tuning:
Configuration Description Example num.partitions Default number of partitions per topic when a new topic is created without specifying the number of partitions. num.partitions=3log.retention.hours Time period for which Kafka retains messages. After this period, messages are eligible for deletion. log.retention.hours=168(7 days)log.segment.bytes Maximum size of a single log segment file. Once this size is reached, Kafka rolls over to a new segment file. log.segment.bytes=1073741824(1 GB)log.cleanup.policy Defines the cleanup policy for logs. Options are delete(removes old logs) andcompact(log compaction for topics with keys).log.cleanup.policy=deletedefault.replication.factor Default replication factor for topics when created. Ensures redundancy and fault tolerance. default.replication.factor=3min.insync.replicas Minimum number of in-sync replicas that must acknowledge a write for the write to be considered successful. Helps in ensuring data durability. min.insync.replicas=2unclean.leader.election.enable Determines if Kafka can elect an out-of-sync replica as leader in case of failure. Disabling this ensures data consistency but might reduce availability. unclean.leader.election.enable=falsenum.network.threads Number of threads handling network requests. Adjust based on the expected load. num.network.threads=3num.io.threads Number of threads for disk I/O operations. Increasing this can improve performance if the broker handles heavy disk activity. num.io.threads=8socket.send.buffer.bytes and socket.receive.buffer.bytes Size of the TCP send and receive buffer sizes. These can be tuned based on network bandwidth and latency. socket.send.buffer.bytes=102400,socket.receive.buffer.bytes=102400 - Security:
Configuration Description Example ssl.keystore.location Path to the SSL keystore used for secure communication /var/private/ssl/kafka.server.keystore.jks ssl.keystore.password Password for the SSL keystore yourpassword ssl.truststore.location Path to the SSL truststore used to verify client certificates /var/private/ssl/kafka.server.truststore.jks ssl.truststore.password Password for the SSL truststore yourpassword - Monitoring and Metrics:
Configuration Description Example metric.reporters A list of classes used to report Kafka metrics. These can integrate with external monitoring systems like Prometheus or JMX. metric.reporters=com.example.MyMetricsReporter log.flush.interval.messages Controls how frequently data is flushed to disk in terms of the number of messages. Lower intervals reduce the risk of data loss but can impact performance. log.flush.interval.messages=10000 log.flush.interval.ms Controls how frequently data is flushed to disk in terms of time interval. Lower intervals reduce the risk of data loss but can impact performance. log.flush.interval.ms=1000 - Zookeeper Configuration:
Configuration Description Example metric.reporters A list of classes used to report Kafka metrics. These can integrate with external monitoring systems like Prometheus or JMX. metric.reporters=com.example.MyMetricsReporter log.flush.interval.messages Controls how frequently data is flushed to disk in terms of the number of messages. Lower intervals reduce the risk of data loss but can impact performance. log.flush.interval.messages=10000 log.flush.interval.ms Controls how frequently data is flushed to disk in terms of time interval. Lower intervals reduce the risk of data loss but can impact performance. log.flush.interval.ms=1000 zookeeper.connect Zookeeper connection string, which includes Zookeeper hosts and ports. Used by brokers to connect to the Zookeeper ensemble. zookeeper.connect=localhost:2181
Apache Kafka APIs
At the heart of Kafka are its APIs, which enable developers to interact with Kafka clusters programmatically. These APIs are used to build robust, real-time data processing applications. In the dynamic world of real-time data streaming, Application Programming Interfaces (APIs) serve as communication endpoints, facilitating seamless interactions between various software applications. Among these, Apache Kafka®’s API stands out, known for its exceptional capabilities in handling real-time data.
Here are list of Kafka APIs:
| API | Description |
|---|---|
| Producer API | Allows applications to send streams of data to topics in the Kafka cluster. |
| Consumer API | Permits applications to read data streams from topics in the Kafka cluster. |
| Streams API | Acts as a stream processor, transforming data streams from input to output topics. |
| Connect API | Enables the development and running of reusable producers or consumers that connect Kafka topics to existing data system applications. |
| Admin API | Supports administrative operations on a Kafka cluster, like creating or deleting topics. |
| Kafka API compatible alternative | Redpanda streaming data platform. |
Apache Kafka provides a rich set of APIs for building real-time data processing applications. Whether you're publishing data to Kafka, consuming messages from Kafka topics, processing data in Kafka streams, managing Kafka clusters, or integrating Kafka with external systems, there's an API available to meet your needs. By understanding and leveraging these APIs effectively, developers can harness the full power of Apache Kafka for building scalable, fault-tolerant, and real-time data pipelines.
Kafka API use cases
Some use cases for Kafka API include:
- Real-time analytics: Kafka API is instrumental in powering real-time analytics in various fields. By consuming data streams through the Consumer API and producing result streams through the Producer API, real-time analytics engines provide insights as events occur, aiding in prompt decision-making.
- Event sourcing: Event sourcing is a programming paradigm that saves all changes to the application state as a sequence of events. Kafka APIs enhance system traceability and debugging in event streaming. They handle, store, and process large event streams at scale.
- Log aggregation: Log aggregation involves collecting and storing logs from various sources in a centralized location. The Producer API sends logs to Kafka, while the Consumer API consumes these logs. Kafka is a centralized, scalable, and reliable log management solution that aids in monitoring and debugging.
- Message queuing: In a microservices architecture, services often need to communicate with each other. Kafka API facilitates such interactions by acting as a message broker. Messages produced by one service are consumed by another, allowing for effective inter-service communication.
- Stream processing: The Kafka Streams API is used in applications that require continuous computation and manipulation of data streams, such as real-time data transformation, aggregation, or join operations. You can use them in applications like real-time fraud detection, finance, and live leaderboards in gaming.
Kafka Connect
Advantage of Kafka is its connector system Kafka Connect. Connectors are reusable components which, as the name suggests, allow different systems to be connected to Kafka.
Thus, many technologies provide connectors to transfer data to or from Kafka. For example, if you want to ingest data from a MongoDB database, you can simply install and configure the official MongoDB connector for Kafka. You can see a list of Kafka connectors on the Confluent website (the main contributor of Kafka).
So you can use Kafka Connect to transfer data between two databases through Kafka, for example to load data from an enterprise application using a relational database into a data lake, without having to code connectors for the source and target systems (sink).
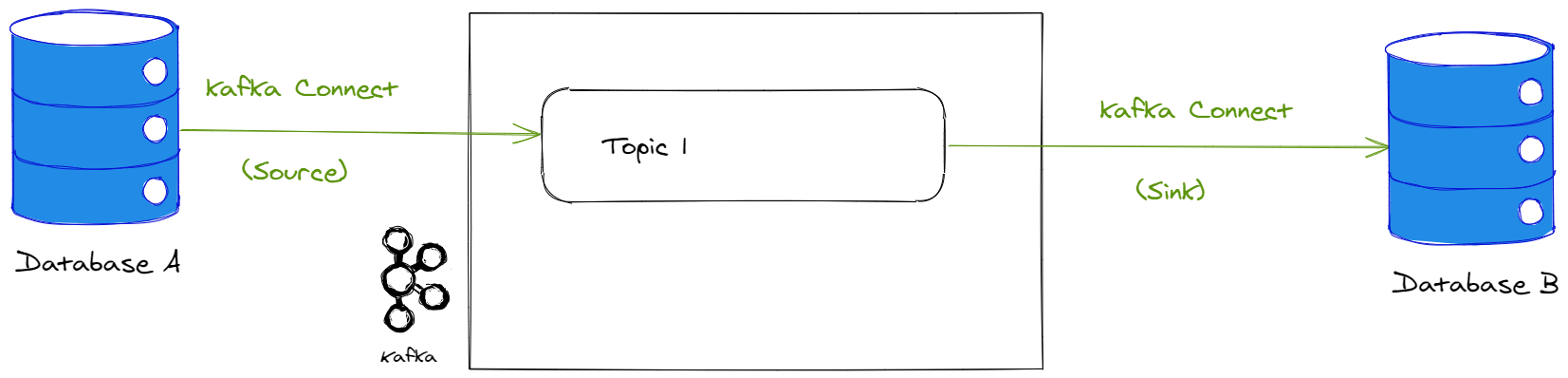
However, when transferring this type of data, it is often necessary to carry out an intermediate transformation step (filters, aggregations, etc.). This is called an ETL (Extract Transform Load). There are several tools for performing ETLs (for example Talend). But Kafka can also be used as such, especially by transforming data using the Kafka Streams API.
Kafka Streams
The Kafka Streams API allows us to create derived topics from other topics, by performing transformations on them. This is known as stream processing.
In concrete terms, Kafka Streams allows you to perform operations such as filters, aggregations (averages, sums, etc.), but also joins between different streams. The resulting stream is persisted in a new topic.
Kafka Streams can be used in conjunction with Kafka Connect to perform ETL:
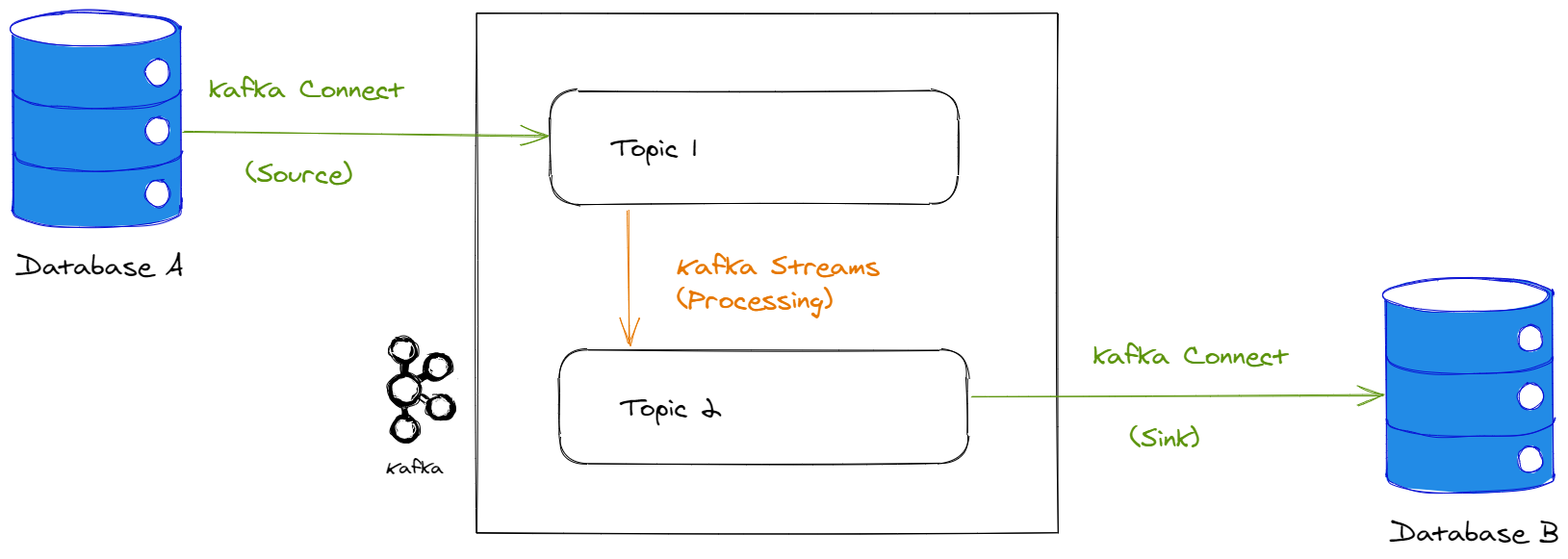
However, it should be noted that Kafka Streams applications must be developed in Java or Scala programming languages, which can be complex to learn. However, there are alternative solutions for stream processing, such as Spark Streaming which has an API in Python.
Kafka installation: set in local machine
Installing Apache Kafka involves several steps, including downloading the Kafka distribution, configuring the environment, starting the Kafka server, and verifying the installation. Below is a guide to help you with the installation process:
- Prerequisites:: Java: Kafka requires Java to be installed on your system. Make sure you have Java installed (To install go to linl and install preferably Java 8 or later)
- Download Kafka:
- Visit the Apache Kafka website (Kafka download page ) and download the latest stable version of Kafka.
- Choose the appropriate binary distribution based on your operating system (e.g., Kafka for Scala 2.13 if you're using Scala 2.13).
Once the download is complete, extract the Kafka archive to a directory of your choice using a file extraction tool (e.g., tar for Linux/Mac or 7-Zip for Windows).
References
- Youtube Kafka tutorial videos (I specially followed this one. Great playlist).
- Apache
- Official Documentation
- Databricks Learning Academy
- Spark by Examples
- Datacamp tutorial.
- For databricks, you can look at tutorial videos on youtube at youtube video by Bryan Cafferky, writer of the book "Master Azure Databricks". A great playlist for someone who just want to learn about the big data analytics at Databricks Azure cloud platform.
- See the video for pyspark basics by Krish Naik. Great video for starter.
- Great youtube on Apache spark one premise working.
Some other interesting things to know:
- Visit my website on For Data, Big Data, Data-modeling, Datawarehouse, SQL, cloud-compute.
- Visit my website on Data engineering