
InsightfulRecruit: Unveiling the Job Market Landscape through Data Engineering
Overview
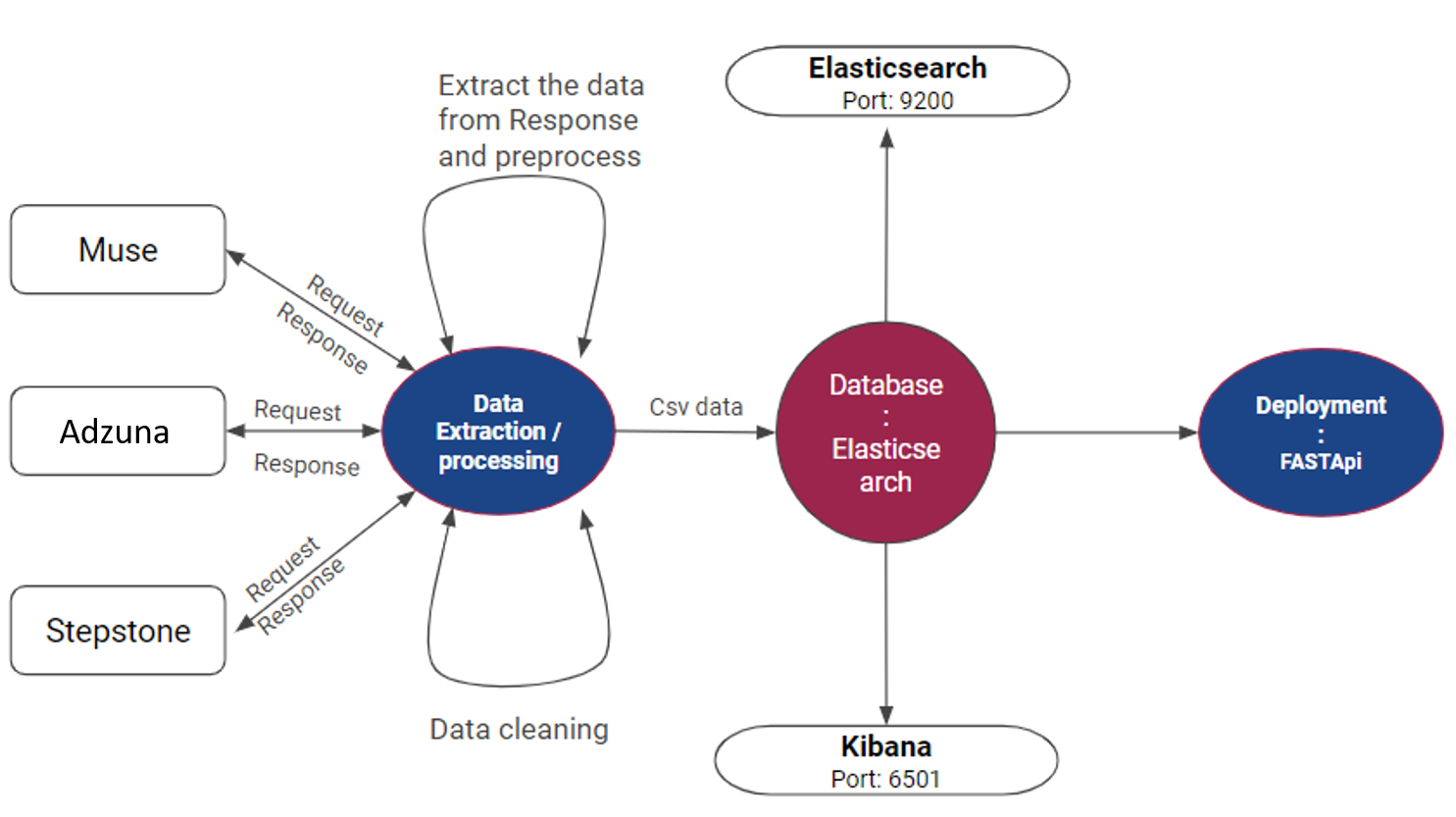
This project aims to showcase skills in data engineering by gathering and analyzing job market data from various sources. By the end of the project, we aim to have a clearer understanding of the job market, including sectors with the highest demand, required skills, active cities, and more.Prerequisite
- WebScrapping: BeautifulSoup, Selenium, Adzuna API, Muse API
- Python: -3.10.x
- NoSQL: ElasticSearch
- Docker Compose: Docker v2.15.1
- API: fastAPI
Setup Instructions
- Clone the repository: Clone this Job-Market-project repository to your local machine using Git:
git clone https://github.com/arunp77/Job-Market-Project.gitcd Job-Market-Projectvirtualenv (which can be installed through pip install virtualenv) or conda:
# Using virtualenv
python -m venv env
# activate the enviornment
source env/bin/activate # in mac
env\Scripts\activate # in windows using Command Prompt
.\env\Scripts\Activate.ps1 # in windows using powershell
# Using conda
conda create --name myenv
conda activate myenv
deactivatepip install -r requirements.txtelasticsearch, we must have elasticsearch python clinet installed. Next run the docker-compose.yml first using (detached mode)docker-compose bulddocker-compose up -ddb_connection.py file to integration the elasticsearch using python db_connection.py.
- So the Elasticsearch runs at port: http://localhost:9200/
- So the Kibana runs at port: http://localhost:5601/
db_connection.py script is responsible for establishing a connection to Elasticsearch and loading data into it.
uvicorn api:api --host 0.0.0.0 --port 8000uvicorn api:api --reload- docs_url: Specifies the URL path where the OpenAPI (Swagger UI) documentation will be available. By default, it's set to /docs and can be accessed at http://localhost:8000/api/docs.
- redoc_url: Specifies the URL path where the ReDoc documentation will be available. By default, it's set to /redoc and can be accessed to http://localhost:8000/api/redoc.
For more details on the project: please check the github repo. A demo video of the project is available at:

References
Some other interesting things to know:
- Visit my website on For Data, Big Data, Data-modeling, Datawarehouse, SQL, cloud-compute.
- Visit my website on Data engineering