
Elasticsearch
Introduction
Elasticsearch is a open source distributed RESEful search and analytics engine commonly used for large-scale data processing. It's widely employed in data engineering and analytics for efficient searching, indexing, and analysis of diverse datasets. It is often used to enable search functionality for applications and websites.
For example: Imagine an online shop where you want users to be able to search for different types of data. This could be blog posts, products, categories, etc ... You can create a complex search functionality with Elasticsearch similar to what you see on Google. This includes auto-completion, typo correction, highlighting matches, managing synonyms, adjusting relevance, etc. If products have ratings, select highly rated products.
Basically, Elasticsearch can do everything you would need to build a powerful search engine. The tool integrates seamlessly into data pipelines and allows you to exploit data sent from a data warehouse for example.
Elasticsearch is written in Java and is built on top of Apache Lucene which is a NoSQL technology. Elasticsearch has gained popularity because of its relative ease of use and because of its very active community.
Application
It powers a variety of use cases, including:- Real-time search: Elasticsearch can quickly and efficiently search large datasets, making it ideal for applications that need to provide real-time insights into data.
- Full-text search: Elasticsearch supports full-text search, which enables you to search for documents based on their content, including text, numbers, and dates.
- Logs: Elasticsearch can be used to store and analyze logs from a variety of sources, such as servers, applications, and networks. This can help you identify and troubleshoot problems quickly.
- Metrics: Elasticsearch can be used to store and analyze metrics data, such as CPU usage, memory usage, and network traffic. This can help you monitor the performance of your systems and applications.
- Application performance monitoring (APM): Elasticsearch is a key component of the Elastic APM stack, which provides a unified view of application performance data. This can help you identify and fix performance bottlenecks.
- Security logs: Elasticsearch can be used to store and analyze security logs, such as logs from firewalls, intrusion detection systems, and web application firewalls. This can help you identify and respond to security threats quickly.
Benefits
Here are some of the benefits of using Elasticsearch:- Scalability: Elasticsearch is designed to be highly scalable, so it can be easily adapted to handle increasing data volumes and usage demands.
- Real-time search: Elasticsearch can provide real-time search results, which is important for applications that need to keep up with the latest data.
- Flexibility: Elasticsearch is a very flexible tool, and it can be used to store and analyze a variety of data types.
- Search relevance: Elasticsearch uses a variety of techniques to improve search relevance, so users can find the information they need quickly and easily.
- Community support: Elasticsearch has a large and active community, so there are plenty of resources available to help you learn and use the tool.
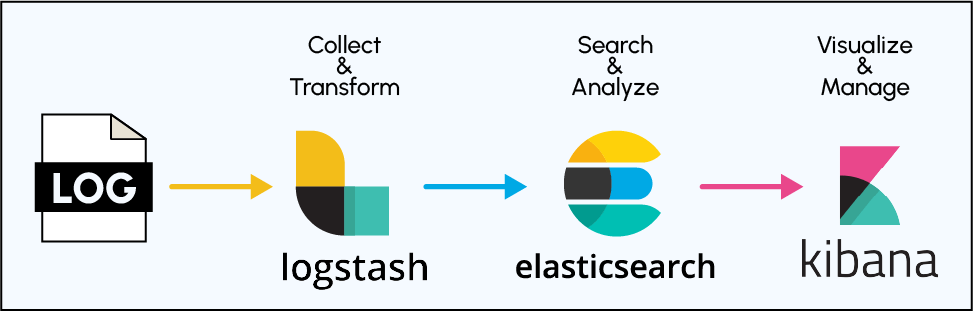
The Elastic (ELK) suite
The ELK suite is an acronym often used to describe a suite that includes three popular projects:- Elasticsearch: It's a distributed search and analytics engine. Elasticsearch is used for indexing and searching large volumes of data quickly.
- Logstash: This is a server-side data processing pipeline that ingests data from multiple sources, transforms it, and sends it to a "stash" like Elasticsearch.
- Kibana: A data visualization dashboard that allows users to interact with data stored in Elasticsearch. It provides real-time analytics, visualizations, and various dashboards.
Historically, these tools were popular for managing logs and information generated by servers (or other information system machines) because of the interportability of the ELK suite tools. That is to say its capacity to manage documents of any nature and format.
The data storage format
In Elasticsearch, data is stored as document and in a format called JSON (JavaScript Object Notation) and these documents can be queried and interacted with via a REST API.
JSON is a lightweight and human-readable data interchange format. It consists of key-value pairs and arrays, making it well-suited for representing structured data.
When you index documents in Elasticsearch, each document is essentially a JSON object. These documents are stored in indices, and each field within a document is a key-value pair. Here's a simple example of a JSON document representing an employee:
{
"employee_id": 1,
"first_name": "John",
"last_name": "Doe",
"age": 30,
"department": "IT",
"salary": 80000
}
In this example, "employee_id," "first_name," "last_name," "age," "department," and "salary" are fields, and their corresponding values are the data associated with those fields.
Elasticsearch uses its own internal data structures and algorithms to index and store this JSON data efficiently, allowing for fast and scalable search and retrieval operations.
Indexes
- A set of documents is stored in an index. Each index therefore contains a group of documents assembled in a logical way. In comparison, an index in Elasticsearch corresponds to a database in a relational SQL database and can represent a list of users, articles, countries, etc.
- An index is therefore a collection of documents that have similar characteristics and are logically related. An index can contain as many documents as you want, there is no strict limit. However, care must be taken to keep a certain consistency in the indexes.
- As Elasticsearch is a distributed system by nature, it works with a system of nodes and scales very well in terms of increasing data volumes and query throughput. Each index is stored in a node of the ES cluster.
The node system
- A node is essentially an Elasticsearch instance that stores data. If our system contains 3 nodes, that means our data is spread across 3 separate ES instances.
- A node refers to an instance of Elasticsearch, not a machine, so you can run any number of nodes on the same machine. A cluster is a collection of linked nodes that together contain all the data.
- Clusters are completely independent and isolated from each other by default. It is possible to perform inter-cluster searches, but it is not very common to do so. An Elasticsearch node will always be part of a cluster, even if there are no other nodes.
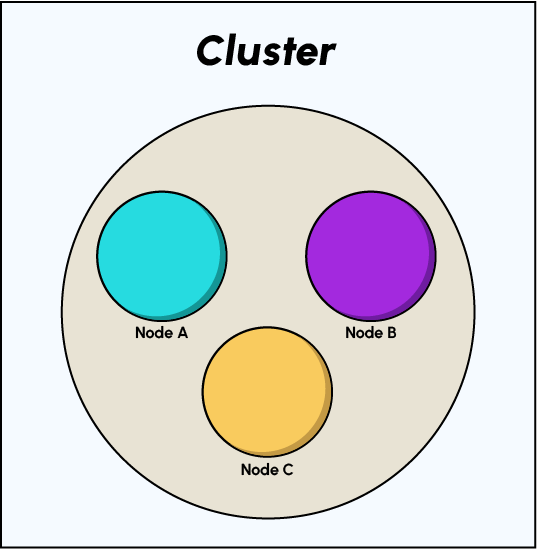
You have learned how a cluster of one or more nodes is composed. This is how Elasticsearch manages data storage and disk space.
Sharding
Sharding is a key concept in Elasticsearch that enables horizontal scalability and improves query performance. It involves dividing an index into multiple smaller chunks called shards or fragments, which are distributed across multiple nodes in a cluster. This allows Elasticsearch to handle large datasets and handle more search queries simultaneously.Example: Suppose we have two 500 gigabyte nodes and a huge 600 gigabyte index, which means that the entire index does not fit on any of the nodes.
Instead, we can split the index into two shards or fragments, each requiring 300 gigabytes of disk space. We can now store a fragment on each of the two nodes without
running out of disk space.
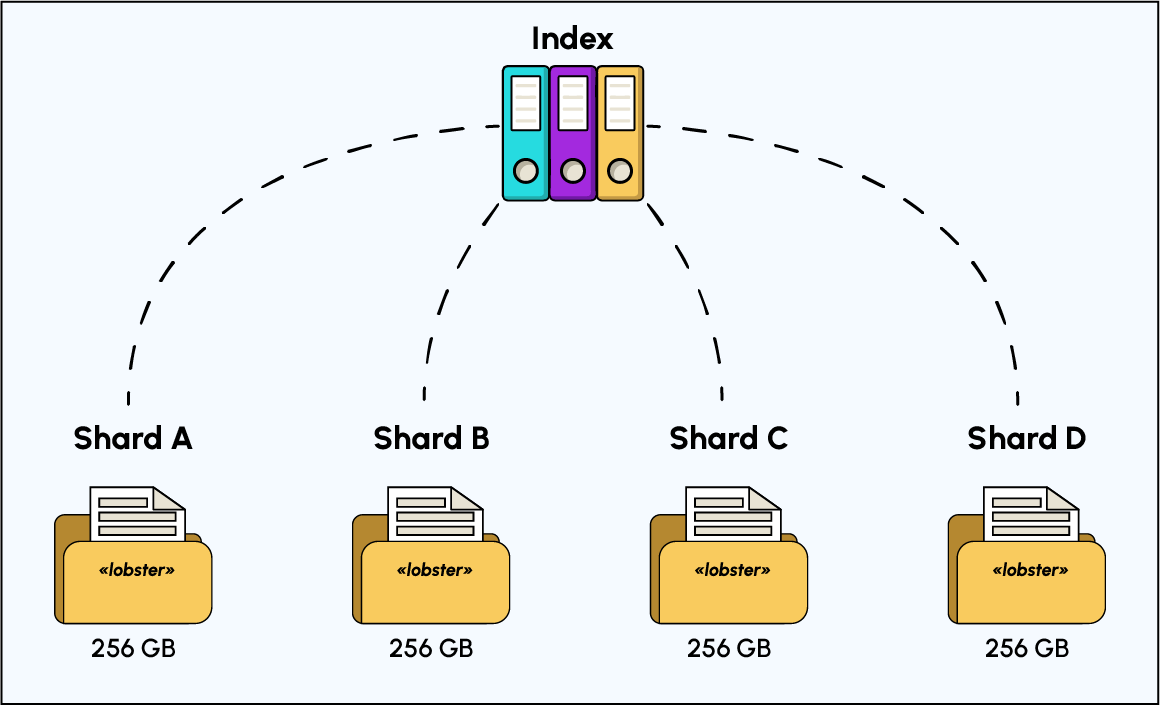
Benefits of Sharding in Elasticsearch
- Horizontal Scalability: By distributing data across multiple shards and nodes, sharding allows Elasticsearch to handle increasing data volumes without requiring a single node to store the entire dataset. This makes Elasticsearch highly scalable for large-scale deployments.
- Improved Query Performance: Sharding enables parallelization of indexing and search operations, which can significantly improve query performance. With multiple shards handling search requests, queries can be processed more efficiently and reduce response times.
- Data Redundancy and Fault Tolerance: Sharding provides redundancy by replicating shards across multiple nodes. This ensures that data remains accessible even if a node fails, preventing data loss and downtime.
How Sharding Works in Elasticsearch:
- Index Creation: When an index is created, the number of shards is specified. Each shard is a self-contained Lucene index, capable of indexing, searching, and managing documents.
- Shard Distribution: Shards are distributed across nodes in the cluster based on a predefined allocation strategy. This strategy aims to distribute shards evenly among nodes to balance the load and ensure efficient data access.
- Query Routing: When a search query is initiated, Elasticsearch routes the query to the appropriate shards based on the query predicate. This allows different parts of the query to be processed simultaneously across multiple shards.
- Shard Merging: As shards accumulate data, they may become large, impacting performance. Elasticsearch periodically merges smaller shards into larger ones to optimize performance and reduce index size.
Replication
When we talked about sharding, you learned that an index consists of a single fragment by default.But what happens if the node where a fragment is stored fails ?
The answer is simple : the data is lost because we have no copy of it. This is obviously a major problem, as the hardware can fail at any time. The more hard drives you use to run your cluster, the higher the chance of failure. So we need some fault tolerance and failover mechanism, which is where replication comes in. Elasticsearch natively supports replication of shards, and this is in fact enabled by default.How does replication work in Elasticsearch ?
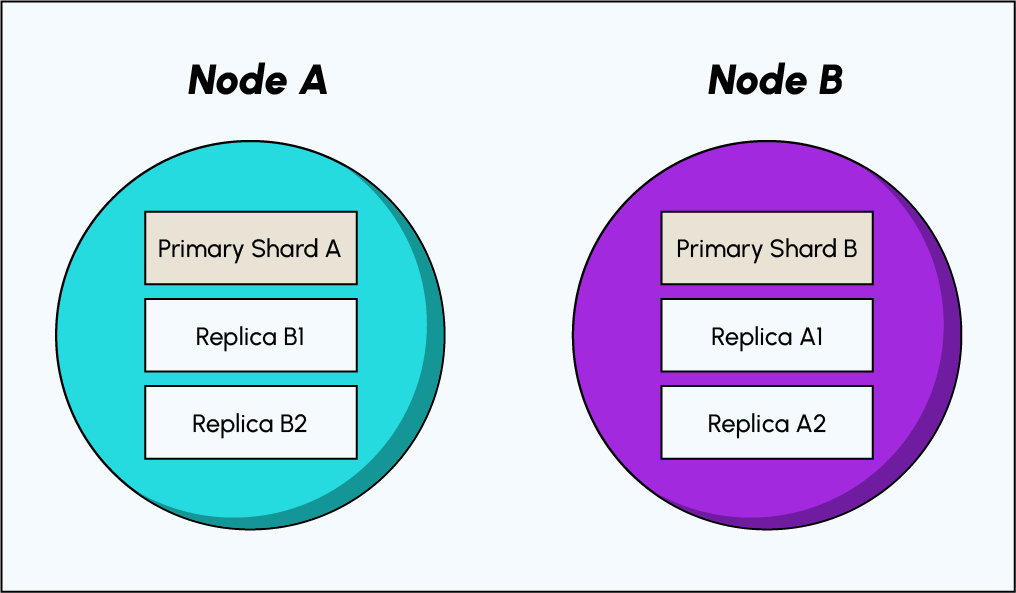
principal shards fragment.
A principal shard and its replication shards are called a replication group. When creating an index, we can choose how many replicas of each shard we want, with 1 being the default. For the sake of resiliencies, replica fragments are never stored on the same node as their main fragment.
This means that if a node disappears, there will always be at least one copy of the data from a fragment available on a different node. Replication only makes sense for clusters that contain more than one node.
References
- Getting Started with Elasticsearch
- This content is part of my study of a module on Elastic search provided by Datascientist.
Some other interesting things to know:
- Visit my website on For Data, Big Data, Data-modeling, Datawarehouse, SQL, cloud-compute.
- Visit my website on Data engineering