Methods of Parameter Estimation in Statistical Modeling
"Exploring Techniques, Strengths, and Limitations Across Diverse Approaches"
Introduction
Explaining the fundamentals of Machine Learning and Statistical Modeling in simple terms can be challenging due to the existing confusion. In this discussion, our goal is to unravel these concepts, elucidating what they entail, highlighting their distinctions, and exploring their practical applications.
Machine Learning is a subfield of artificial intelligence (AI) that focuses on the development of algorithms and models that enable computers to learn patterns and make decisions without being explicitly programmed. The primary goal is to allow systems to improve their performance on a specific task as they are exposed to more data.
Key Characteristics:
Learning from Data: ML algorithms learn patterns and relationships from data, allowing them to generalize to new, unseen instances
Prediction and Decision-Making: ML is often used for tasks such as prediction, classification, clustering, and decision-making. Common algorithms include regression, support vector machines, decision trees, and neural networks
Adaptability: ML models can adapt to changing conditions and new information, making them suitable for dynamic and complex scenarios
Applications: Widely used in applications like image and speech recognition, natural language processing, recommendation systems, autonomous vehicles, and more.
2. Statistical modeling:
Statistical Modeling is a method used in statistics to describe relationships between variables and make inferences about populations based on observed data. It involves the formulation of mathematical models that represent the structure of the data and the underlying processes generating that data.
Key Characteristics:
Parameter Estimation: Statistical models often involve estimating parameters that describe the relationships between variables. This includes methods like linear regression, logistic regression, and generalized linear models.
Hypothesis Testing: Statistical modeling includes hypothesis testing to assess the validity of assumptions and draw conclusions about the significance of observed effects.
Uncertainty and Variability: Statistical models account for uncertainty and variability in data through concepts like confidence intervals, p-values, and standard errors.
Applications: Commonly used in scientific research, social sciences, economics, epidemiology, and various fields where understanding the relationships between variables and making predictions based on data are essential.
Comparison:
Aspect
Machine Learning (ML)
Statistical Modeling
Objective
The goal is to develop algorithms for predictions without explicit programming.
Focuses on describing relationships, making inferences, and understanding uncertainty.
Flexibility
More flexible, adapts to complex patterns and non-linear relationships.
Generally more rigid, relies on explicit assumptions about data distribution.
Assumptions
May not make strong assumptions about data distribution.
Makes explicit assumptions about data distribution and variable relationships.
Interpretability
May lack interpretability, especially in complex models like deep neural networks.
Typically provides more interpretable results using coefficients, p-values, etc.
Data Size
Beneficial for large datasets, especially deep learning models.
Can be applied to smaller datasets, emphasizes sampling methods and statistical significance.
Application Areas
Used in image recognition, natural language processing, recommendation systems, etc.
Applied in traditional statistical analyses, epidemiology, economics, social sciences, etc.
Methods of Parameter Estimation in Statistical Modeling
Understanding and estimating parameters in statistical models is a fundamental aspect of data analysis. This comprehensive guide explores various parameter estimation methods, offering insights into their strengths, limitations, and applicability in different scenarios.
Least Squares Estimation:
A common use of least-squares minimization is curve fitting, where one has a parametrized model function meant to explain some phenomena and wants to adjust the numerical values for the model so that it most closely matches some data.
Method: Minimizes the sum of squared differences between observed and predicted values.
Objective Function:
Minmize: $$\sum_{i=1}^n (y_i - f(x_i, \theta))^2$$
where yi is the observed value, f(xi, θ) is the model prediction, and θ are the parameters.
Python library used: scipy.optimize
Example code:
from scipy.optimize import curve_fit
def model_function(x, a, b):
return a * x + b
params, covariance = curve_fit(model_function, x_data, y_data)
Strengths:
Simple and widely used.
Straightforward to implement.
Limitations:
Sensitive to outliers.
Assumes normally distributed errors.
Maximum Likelihood Estimation (MLE):
Method: Maximizes the likelihood function, which measures how well the model explains the observed data.
Objective Function:
Maximize $$\mathcal{L}(\theta; y) = \Pi_{i=1}^n f(y_i; \theta)$$
here L is the likelihood function, yi are observed values, and
f(.; θ) is the probability density function.
Python library used: statsmodels
Example code:
import statsmodels.api as sm
model = sm.OLS(y_data, sm.add_constant(x_data))
results = model.fit()
Strengths:
Asymptotically efficient (efficient as sample size approaches infinity).
Provides confidence intervals.
Limitations:
Sensitive to distributional assumptions.
Can be computationally intensive.
Bayesian Estimation:
Method: Combines prior knowledge with observed data to update probability distributions over parameters.
Posterior Distribution:
$$P(\theta | y) \propto \mathcal{L}(\theta; y) \times P(\theta)$$
here P(θ | y) is the posterior distribution, L is the likelihood, and P(θ) is the prior distribution.
Python library used: pymc3
Example code:
import pymc3 as pm
with pm.Model() as model:
# Define priors
theta = pm.Uniform('theta', lower=0, upper=1)
# Define likelihood
likelihood = pm.Normal('likelihood', mu=model_prediction, sd=observed_data_sd, observed=observed_data)
# Run Bayesian inference
trace = pm.sample(1000)
Strengths:
Incorporates prior information.
Provides posterior distribution for parameters.
Limitations:
Requires specifying a prior, which can be subjective.
Provides estimates consistent with sample moments.
Limitations:
May not perform well for small sample sizes.
Assumes the population moments match the sample moments.
Generalized Method of Moments (GMM):
Method: Minimizes a criterion function based on sample moments and model-implied moments.
Objective Function:
$$\text{Minmize}~ Q(\theta) = (g(\theta)' {\bf W} g(\theta))^T$$
where \( g(\theta) \) is the vector of moments, \(W\)
Python library used: statsmodels
Example code:
from statsmodels.sandbox.regression.gmm import GMM
class GMMModel(GMM):
def momcond(self, params):
# Define moment conditions
return ...
model = GMMModel(...)
results = model.fit()
Strengths:
More flexible than the method of moments.
Allows for testing the validity of the assumed model.
Limitations:
Requires specifying a moment condition.
Sensitive to the choice of moments.
Regression Analysis:
Method: Regression analysis models the relationship between a dependent variable and one or more independent variables using a regression equation. The goal is to understand and quantify the relationship between variables
Regression Equation:
$$Y = \beta_0 +\beta_1 X_1 + ... + \beta_k X_k + \epsilon$$
where \(\beta_i\) are coefficients, \(\epsilon\) is the error term.
Python library used: statsmodels
Example code:
import statsmodels.api as sm
X = sm.add_constant(x_data)
model = sm.OLS(y_data, X)
results = model.fit()
Strength:
Widespread Use: Regression is one of the most widely used statistical techniques in various fields.
Insights into Relationships: It provides insights into how changes in independent variables relate to changes in the dependent variable.
Limitations:
Assumes a Specific Form: Regression assumes a specific functional form for the relationship, which may not always reflect the true nature of the data.
Multicollinearity: High correlations among independent variables can lead to multicollinearity issues, making it challenging to isolate the individual effects of variables.
Optimization Methods:
Method: Optimization methods aim to find the minimum or maximum of an objective function by iteratively adjusting the parameters of the model. These methods are commonly used in parameter estimation.
Objective Function:
Minimize or Maximize $$f(\theta)$$
where \(f(\theta)\) is the objective function representing the problem.
Python library used: scipy.optimize
Example code:
from scipy.optimize import minimize
result = minimize(objective_function, initial_guess, args=(x_data, y_data))
Strengths:
Flexibility: Optimization is a versatile approach applicable to various problems.
Algorithmic Diversity: There is a wide range of optimization algorithms available, each suitable for different types of problems.
Limitations:
Sensitivity to Initial Guesses: The convergence of optimization methods, especially gradient-based ones, can be sensitive to the initial guesses for the parameters.
Global Optimum Challenge: There's no guarantee that the optimization process will converge to the global optimum, and it may get stuck in local minima or maxima.
\(\)
Bootstrap Methods:
Method: Bootstrap methods involve resampling the dataset with replacement to create multiple bootstrap samples. These samples are then used to estimate sampling distributions and assess parameter precision.
Resampling Procedure:
$$\theta^* = \text{Estimator from Bootstrap Sample}$$
Repeat resampling to construct the sampling distribution of the estimator.
Python library used: numpy
Example code:
import numpy as np
def estimate_with_bootstrap(data, num_iterations):
estimates = []
for _ in range(num_iterations):
bootstrap_sample = np.random.choice(data, size=len(data), replace=True)
estimate = calculate_estimate(bootstrap_sample) # Your estimation function
estimates.append(estimate)
return np.array(estimates)
Strengths:
Non-parametric: Bootstrap is non-parametric and does not rely on distributional assumptions.
Parameter Precision: It is useful for estimating the precision of parameters and constructing confidence intervals.
Limitations:
Computational Intensity: The computational cost can be high for large datasets or complex models because it involves repeatedly resampling the data
Representative Sample Assumption: Bootstrap assumes that the original sample is representative of the population, and this might not always hold.
Choosing the most suitable method depends on the specific characteristics of the data and the problem at hand. Often, a combination of methods or model diagnostics is employed to assess the reliability of parameter estimates. It's essential to consider the assumptions and limitations of each method and tailor the approach to the characteristics of the dataset and the goals of the analysis.
Exploring the Role of Initial Guesses in Parameter Estimation: Considerations
Whether you need an initial guess for parameter estimation depends on the specific method used. Let's discuss the role of initial guesses in various parameter estimation methods:
Initial guesses influence the optimization process.
Convergence may depend on the quality of the initial guess.
Considerations:
Choose initial values close to the true parameters if possible.
Experiment with different initial guesses to ensure convergence.
Curve Fitting (e.g., `curve_fit` in `scipy.optimize.curve_fit`):
Role of Initial Guess:
The p0 parameter in curve_fit provides initial guesses for the parameters.
Better initial guesses can lead to faster and more accurate convergence
Considerations:
Provide reasonable initial guesses based on your understanding of the data.
MLE and Bayesian Methods:
Role of Initial Guess:
Initial values can affect convergence and the resulting estimates.
Particularly relevant when optimization methods are used for MLE or Bayesian estimation.
Considerations: Experiment with different initial values to check robustness
Methods that May Not Require Initial Guesses (or Less Sensitive):
Method of Moments:
Role of Initial Guess:Less sensitive to initial guesses compared to optimization-based methods.
Considerations: Often more robust, but still be mindful of potential issues.
Bootstrap Methods:
Role of Initial Guess:
Bootstrap resampling doesn't rely on an initial guess.
Bootstrap methods are non-parametric and distribution-free.
Considerations: Still need to be cautious with the underlying assumptions.
Least Squares Estimation (e.g., Linear Regression):
Role of Initial Guess: Typically, linear regression doesn't involve an explicit initial guess.
Considerations: The optimization is performed implicitly; be mindful of assumptions.
General Considerations:
Convergence and Global MinimaFor methods that rely on optimization, it's essential to check for convergence and ensure that the optimization algorithm doesn't get stuck in local minima.
Robustness: Always assess the robustness of your parameter estimates by trying different starting points or initial guesses.
Distributional Assumptions: Be aware of the assumptions underlying each method. Some methods, especially in Bayesian estimation, may be less sensitive to initial guesses but have other requirements.
Example of exponential function curve fitting:
When confronted with a collection of data points exhibiting a noticeable rapid increase, it can be beneficial to employ a smooth, exponentially increasing curve to effectively capture and describe the overall trend of the data.
The line that you need to fit in order to achieve this shape will be one that is described by an exponential function, that is any function of the form:
$$y=A\times B^x +C$$
or
$$y=ae^{bx}+c$$
(these two are mathematically equivalent because \(AB^x = Ae^{x\text{ln}(B)}\)).
Method to fit the curve:
polyfit method: This method only works when \(c=0\), i.e when you want to fit a curve with equation \(y = a e^{bx}\) to the data. For a cirve with \(y = ae^{bx}+c\), second method us useful.
The polyfit() command from Numpy is used to fit a polynomial function to data.
Polyfit (see the source):
In mathematics and computer science, polyfit is a general term for fitting a polynomial to a set of data points. This means finding the polynomial that best approximates the data points in terms of minimizing the squared error between the polynomial and the data points.
The polyfit function is a common tool in many numerical analysis and scientific computing libraries. It is used to fit polynomials to data for a variety of purposes, such as data smoothing, interpolation, and curve fitting.
This fit a polynomial
$$p(x) = p[0]\times x^n + p[1]\times x^{n-1} + p[2]\times x^{n-2} .... + p[n]$$
n is the degree of the polynomoal to the data points (x, y).
For n=1 (degree=1), \(p(x) = p[0] x+ p[1]\)
For n=2, (degree=2), \(p(x) = p[0] x^2+ p[1] x +p[2]\) \(\)
For n=1, (degree=3), \(p(x) = p[0] x^3+ p[1] x^2 + p[2] x + p[3]\) \(\)
where the coefficients \(p[i]\) are the coefficients of the polynomials and can be calculated using the polyfit method. Here \(n\) is the degree of the polynomial.
his method takes a set of data points and the desired degree of the polynomial as input and returns the coefficients of the polynomial that best fits the data points.
The coefficients are calculated by miimizing the square errors:
$$E=\sum_{j=0}^k |p(x_j) - y_j|^2$$
in the equations:
\[
\begin{align*}
x[0]^n \cdot p[0] + \ldots + x[0] \cdot p[n-1] + p[n] &= y[0] \\
x[1]^n \cdot p[0] + \ldots + x[1] \cdot p[n-1] + p[n] &= y[1] \\
&\vdots \\
x[k]^n \cdot p[0] + \ldots + x[k] \cdot p[n-1] + p[n] &= y[k] \\
\end{align*}
\]
The coefficient matrix of the coefficients p is a Vandermonde matrix.
numpy.polyfit(x, y, deg, rcond=None, full=False, w=None, cov=False)
This might seem a little strange: why are we trying to fit a polynomial function to the data when we want to fit an exponential
function? The answer is that we can convert an exponential function into a polynomial one using the fact that:
$$y = a e^{bx} \Rightarrow \text{ln} = \text{ln}(a)+bx.$$
because we can take the natural logarithm of both sides. This creates a linear equation \(f(x) = mx+c\) where:
\(f(x) = \text{ln}(y) \)
\(m = b = p[0]\)
\(c = \text{ln}(b) = p[1]\)
so polyfit can be used to fit \(\text{ln}(y)\) against \(x\):
import numpy as np
# Set a seed for the random number generator so we get the same random numbers each time
np.random.seed(20210706)
# Create fake x-data
x = np.arange(10)
# Create fake y-data
a = 4.5
b = 0.5
c = 0
y = a * np.exp(b * x) + c # Use the second formulation from above i.e. f(x) = mx+c
y = y + np.random.normal(scale=np.sqrt(np.max(y)), size=len(x)) # Add noise
# Fit a polynomial of degree 1 (a linear function) to the data
p = np.polyfit(x, np.log(y), 1)
This polynomial can now be converted back into an exponential:
# Convert the polynomial back into an exponential
a = np.exp(p[1])
b = p[0]
x_fitted = np.linspace(np.min(x), np.max(x), 100)
y_fitted = a * np.exp(b * x_fitted)
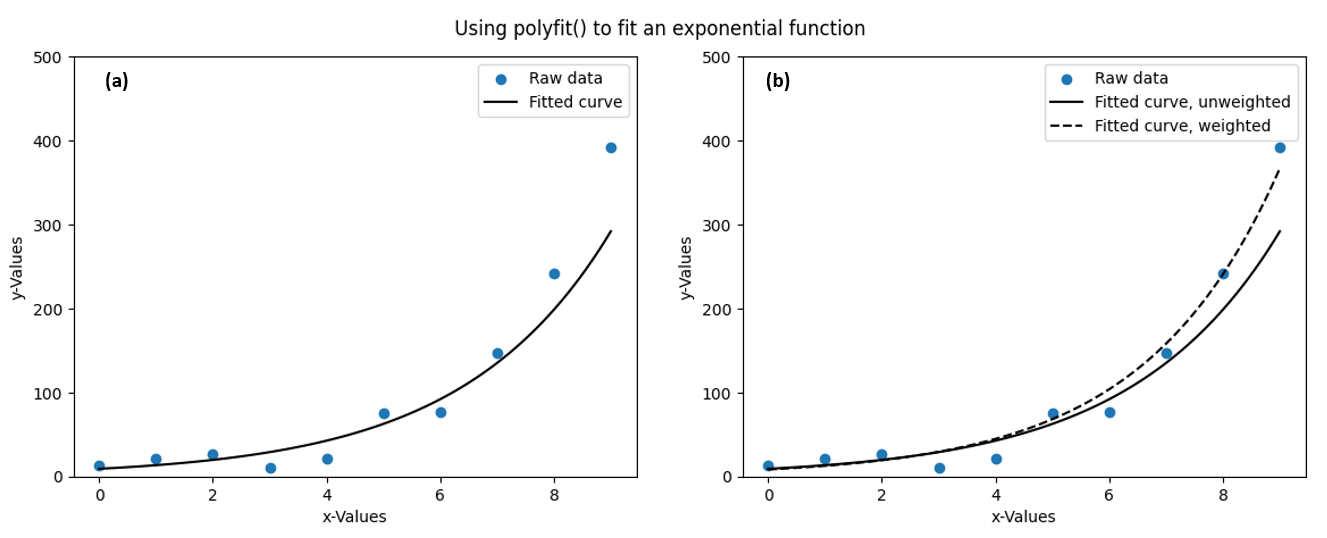
Let’s take a look at the fit:
import matplotlib.pyplot as plt
ax = plt.axes()
ax.scatter(x, y, label='Raw data')
ax.plot(x_fitted, y_fitted, 'k', label='Fitted curve')
ax.set_title('Using polyfit() to fit an exponential function')
ax.set_ylabel('y-Values')
ax.set_ylim(0, 500)
ax.set_xlabel('x-Values')
ax.legend()
See the image-(a) below.
This method has the disadvantage of over-emphasising small values: points that have large values and
which are relatively close to the linear line of best fit created by polyfit() become much further
away from the line of best fit when the polynomial is converted back into an exponential. The act of
transforming a polynomial function into an exponential one has the effect of increasing large values
much more than it does small values, and thus it has the effect of increasing the distance to the fitted
curve for large values more than it does for small values. This can be mitigated by adding a ‘weight’ proportional to y
: tell polyfit() to lend more importance to data points with a large y-value:
# Fit a weighted polynomial of degree 1 (a linear function) to the data
p = np.polyfit(x, np.log(y), 1, w=np.sqrt(y))
# Convert the polynomial back into an exponential
a = np.exp(p[1])
b = p[0]
x_fitted_weighted = np.linspace(np.min(x), np.max(x), 100)
y_fitted_weighted = a * np.exp(b * x_fitted_weighted)
# Plot
ax = plt.axes()
ax.scatter(x, y, label='Raw data')
ax.plot(x_fitted, y_fitted, 'k', label='Fitted curve, unweighted')
ax.plot(x_fitted_weighted, y_fitted_weighted, 'k--', label='Fitted curve, weighted')
ax.set_title('Using polyfit() to fit an exponential function')
ax.set_ylabel('y-Values')
ax.set_ylim(0, 500)
ax.set_xlabel('x-Values')
ax.legend()
curve_fit method:
From the Scipy pacakge we can get the curve_fit() function. This is more general than polyfit()
(we can fit any type of function we like, exponential or not) but it’s more complicated in that we sometimes need to provide an initial guess as to what the constants could be in order for it to work.
scipy.optimize.curve_fit and scipy.optimize.leastsq are related in that curve_fit is built as a high-level interface on top of leastsq.
Both functions are part of the scipy.optimize module and are used for curve fitting, a process where a mathematical function is adjusted to best fit a set of data points.
scipy.optimize.leastsq: If \(f(x)\) is represents the objective function (the residuals to be minimized), and \(x\) is the vector of parameters to be optimized, leastsq aims to find \(x\) such that:
$$\sum_{i=1}^m \left(f_i(x)\right)^2,$$
where \(f_i(x)\) represents the residuals (differences between the observed and predicted values) for the
\(i-th\) data point.
scipy.optimize.curve_fit: curve_fit is a higher-level function that provides a more user-friendly interface for curve fitting. It is designed to be simple and easy to use.
Internally curve_fit utilizes leastsq for optimization.
Givena model function
$$y = f(x, \theta)$$,
ehere \(\theta\) represents the parameters to be optimized, and a set of data points \((x_i, y_i)\), curve_fit aims to find the optimal parameters \(\theta\) that minimize the difference between the model predictions and the observed data.
mathematically, it can be expressed as:
$$\text{minimize}~ \sum_{i=1}^m (y_i-f(x_i, \theta))^2$$
In essence, curve_fit provides a higher-level abstraction, allowing users to specify a model function and automatically handling the optimization process using leastsq under the hood. The user is shielded from some of the complexities of setting up the optimization problem manually.
Example: Let's consider original example above with \(c\neq 0\):
import numpy as np
from scipy.optimize import curve_fit
import matplotlib.pyplot as plt
# Define the function to fit
def exponential_curve(x, a, b, c):
return a * np.exp(b * x) + c
# Set a seed for the random number generator so we get the same random numbers each time
np.random.seed(20210706)
# Create fake x-data
x = np.arange(10)
# Create fake y-data
a = 4.5
b = 0.5
c = 0
y = a * np.exp(b * x) + c # Use the second formulation from above
y = y + np.random.normal(scale=np.sqrt(np.max(y)), size=len(x)) # Add noise
# Use curve_fit to estimate parameters
params, covariance = curve_fit(exponential_curve, x, y)
# Extract the estimated parameters
a_fit, b_fit, c_fit = params
# Generate points for the fitted curve
x_fitted = np.linspace(np.min(x), np.max(x), 100)
y_fitted = exponential_curve(x_fitted, a_fit, b_fit, c_fit)
# Plot the original data and the fitted curve
plt.scatter(x, y, label='Original Data')
plt.plot(x_fitted, y_fitted, 'r-', label=f'Fitted Curve: y = {a_fit:.2f}exp({b_fit:.2f}x) + {c_fit:.2f}')
plt.xlabel('x')
plt.ylabel('y')
plt.title('Exponential Curve Fitting with curve_fit')
plt.legend()
plt.show()
Note that we need to remove any values that are equal to zero from our y-data (and their corresponding x-values from the x-data) for this to work, although there aren’t any of these in this example data so it’s not relevant here.
here
\[
\begin{align*}
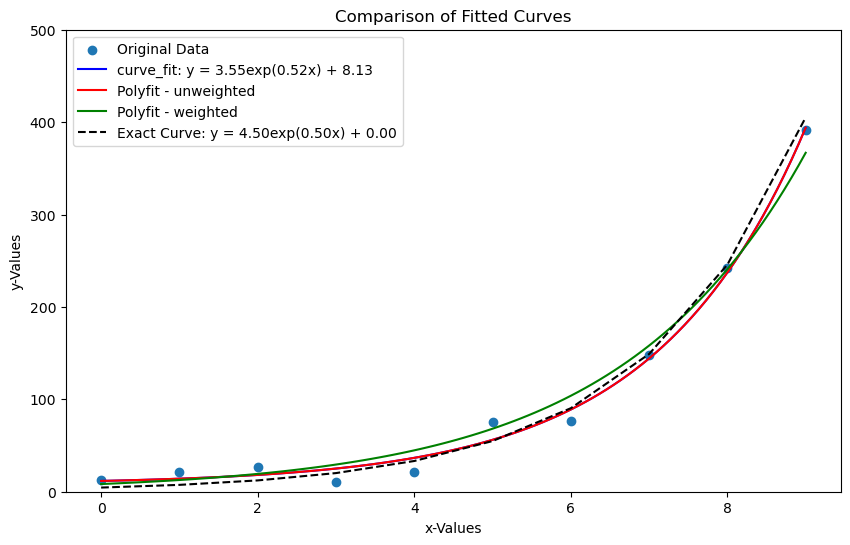
a = \text{params}[0] = 3.5506090736790004 \\
b = \text{params}[1] = 0.5209193547602745\\
c = \text{params}[2] = 8.132855774373255.
\end{align*}
\]
We can compare the fit with the combination of the above two code:
import numpy as np
from scipy.optimize import curve_fit
import matplotlib.pyplot as plt
# Define the function to fit
def exponential_curve(x, a, b, c):
return a * np.exp(b * x) + c
# Set a seed for the random number generator so we get the same random numbers each time
np.random.seed(20210706)
# Create fake x-data
x = np.arange(10)
# Create fake y-data
a = 4.5
b = 0.5
c = 0
y = a * np.exp(b * x) + c # Use the second formulation from above
y = y + np.random.normal(scale=np.sqrt(np.max(y)), size=len(x)) # Add noise
# Use curve_fit to estimate parameters
params, covariance = curve_fit(exponential_curve, x, y)
# Extract the estimated parameters
a_fit, b_fit, c_fit = params
# Generate points for the fitted curve
x_fitted = np.linspace(np.min(x), np.max(x), 100)
y_fitted = exponential_curve(x_fitted, a_fit, b_fit, c_fit)
# Fit a weighted polynomial of degree 1 (a linear function) to the data
p = np.polyfit(x, np.log(y), 1, w=np.sqrt(y))
# Convert the polynomial back into an exponential
a_weighted = np.exp(p[1])
b_weighted = p[0]
x_fitted_weighted = np.linspace(np.min(x), np.max(x), 100)
y_fitted_weighted = a_weighted * np.exp(b_weighted * x_fitted_weighted)
# Exact curve y = ae^{bx}+c
y_exact = a * np.exp(b * x) + c
# Plot all curves in one figure
plt.figure(figsize=(10, 6))
# Original Data and Fitted Curve using curve_fit
plt.scatter(x, y, label='Original Data')
plt.plot(x_fitted, y_fitted, 'b-', label=f'curve_fit: y = {a_fit:.2f}exp({b_fit:.2f}x) + {c_fit:.2f}')
# Unweighted and Weighted Fitted Curves using polyfit
plt.plot(x_fitted, y_fitted, 'r-', label='Polyfit - unweighted')
plt.plot(x_fitted_weighted, y_fitted_weighted, 'g-', label='Polyfit - weighted')
# Exact Curve
plt.plot(x, y_exact, 'k--', label=f'Exact Curve: y = {a:.2f}exp({b:.2f}x) + {c:.2f}')
plt.title('Comparison of Fitted Curves')
plt.xlabel('x-Values')
plt.ylabel('y-Values')
plt.ylim(0, 500)
plt.legend()
plt.show()
As you can see, the curve_fit() method has given us the best approximation of the true underlying exponential behaviour.
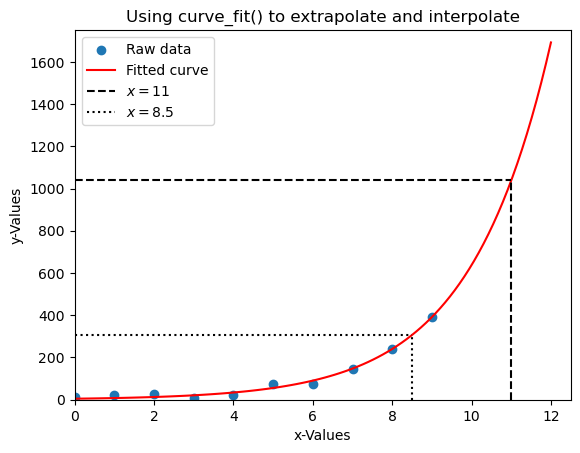
Interpolation and Extrapolation (Forecasting/Predicting/Estimating):
We can use the fitted curve to estimate what our data would be for other values of \(x\)
that are not in our raw dataset: what would the value be at \(x=11\)
(which is outside our domain and thus requires us to forecast into the future) or \(x=8.5\)
(which is inside our domain and thus requires us to ‘fill in a gap’ in our data)? To answer these questions, we simply plug these x-values as numbers into the equation of the fitted curve:
# Fit the function a * np.exp(b * t) to x and y
popt, pcov = curve_fit(lambda t, a, b: a * np.exp(b * t), x, y)
# Extract the optimised parameters
a = popt[0]
b = popt[1]
x_fitted_curve_fit = np.linspace(np.min(x), 12, 100)
y_fitted_curve_fit = a * np.exp(b * x_fitted_curve_fit)
# Extrapolation
y_11 = a * np.exp(b * 11)
# Interpolation
y_8_5 = a * np.exp(b * 8.5)
#
# Plot
#
ax = plt.axes()
ax.scatter(x, y, label='Raw data')
ax.plot(x_fitted_curve_fit, y_fitted_curve_fit, 'k', label=r'Fitted curve')
# Add result of extrapolation
ax.plot([11, 11], [0, y_11], 'k--', label=r'$x=11$')
ax.plot([0, 11], [y_11, y_11], 'k--')
# Add result of interpolation
ax.plot([8.5, 8.5], [0, y_8_5], 'k:', label=r'$x=8.5$')
ax.plot([0, 8.5], [y_8_5, y_8_5], 'k:')
ax.set_title(r'Using curve\_fit() to extrapolate and interpolate')
ax.set_ylabel('y-Values')
ax.set_ylim(0, 1750)
ax.set_xlabel('x-Values')
ax.set_xlim(0, 12.5)
ax.legend()
More explicitly:
print(f'x = 11 implies y = {y_11:6.1f}; x = 8.5 implies y = {y_8_5:5.1f}')
x = 11 implies y = 1038.5; x = 8.5 implies y = 306.7