
Ridge Lasso and Elasticnet Machine learning algorithms
Introduction
Ridge and Lasso regression are regularization techniques used in linear regression to prevent overfitting and improve the model's generalization performance. Both methods introduce a penalty term to the linear regression cost function.Understanding and Addressing Fitting Issues in Machine Learning Models
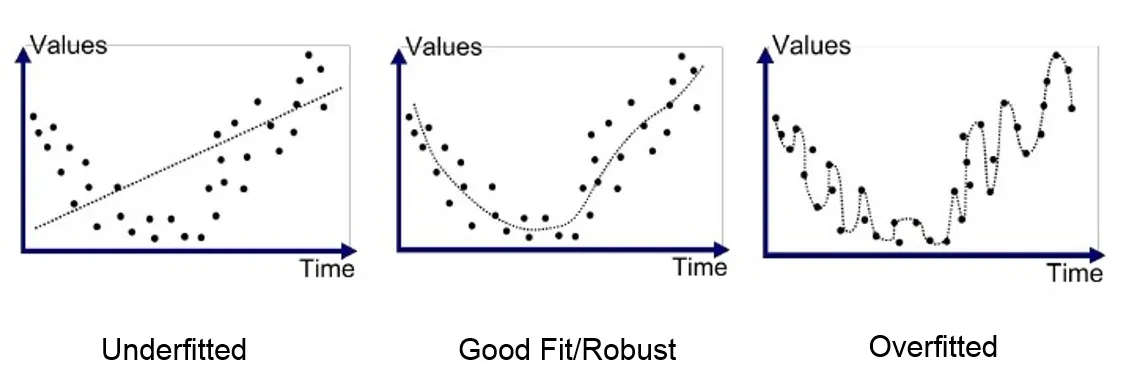
Overfitting and underfitting are two common problems encountered in machine learning. They occur when a machine learning model fails to generalize well to new data.
- Overfitting:
- Description: Overfitting occurs when a machine learning model learns the training data too well, including the noise and irrelevant patterns. As a result, the model becomes too complex and fails to capture the underlying relationships in the data. This leads to poor performance on unseen data.
- Signs of overfitting:
- The model performs well on the training data but poorly on unseen data.
- The model is complex and has a large number of parameters.
- Causes: Too complex model, excessive training time, or insufficient regularization.
- Underfitting
- Description: Underfitting occurs when a machine learning model is too simple and does not capture the underlying relationships in the data. This results in poor performance on both the training data and unseen data.
- Signs of underfitting:
- The model performs poorly on both the training data and unseen data.
- The model is simple and has a small number of parameters.
- Causes: Model complexity is too low, insufficient training, or inadequate feature representation.
- Bias (Systematic Error):
- Description: The model consistently makes predictions that deviate from the true values.
- Symptoms: Consistent errors in predictions across different datasets.
- Causes: Insufficiently complex model, inadequate feature representation, or biased training data.
- Variance (Random Error):
- Description: The model's predictions are highly sensitive to variations in the training data.
- Symptoms: High variability in predictions when trained on different subsets of the data.
- Causes: Too complex model, small dataset, or noisy training data.
- Data Leakage:
- Description: Information from the validation or test set inadvertently influences the model during training.
- Symptoms: Overly optimistic evaluation metrics, unrealistic performance.
- Causes: Improper splitting of data, using future information during training.
- Model Instability:
- Description: Small changes in the input data lead to significant changes in model predictions.
- Symptoms: Lack of robustness in the model's performance.
- Causes: Sensitivity to outliers, highly nonlinear relationships.
- Multicollinearity:
- Description: High correlation among independent variables in regression models.
- Symptoms: Unstable coefficient estimates, difficulty in isolating the effect of individual variables.
- Causes: Redundant or highly correlated features.
- Imbalanced Data:
- Description: A disproportionate distribution of classes in classification problems.
- Symptoms: Biased models toward the majority class, poor performance on minority classes.
- Causes: Inadequate representation of minority class, biased sampling.
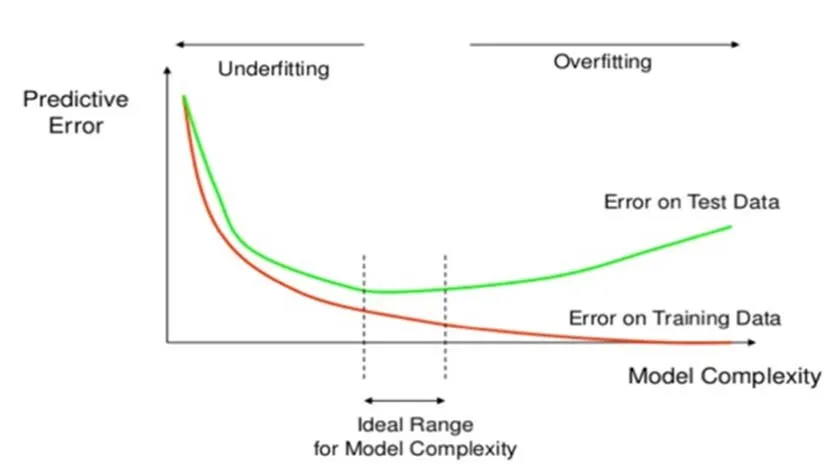
Preventing Overfitting and Underfitting
There are a number of techniques that can be used to prevent overfitting and underfitting. These include: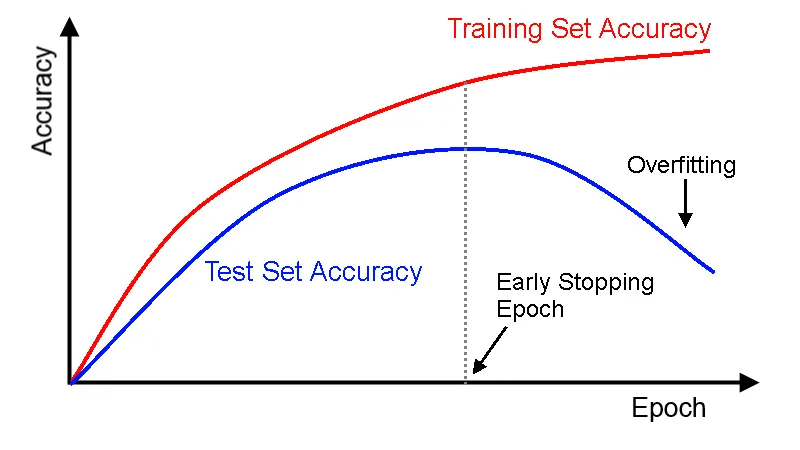
- Regularization: Regularization is a technique that penalizes complex models. This helps to prevent the model from learning the noise and irrelevant patterns in the training data. Common regularization techniques include L1 regularization, L2 regularization, and dropout.
- Early stopping: Early stopping is a technique that stops training the model when it starts to overfit on the validation data. The validation data is a subset of the training data that is held out during training and used to evaluate the model's performance.
- Cross-validation: Cross-validation is a technique that divides the training data into multiple folds. The model is trained on a subset of the folds and evaluated on the remaining folds. This process is repeated multiple times so that the model is evaluated on all of the data. Cross-validation can be used to select the best hyperparameters for the model.
- Model selection: Model selection is a technique that compares different models and selects the one that performs best on the validation data. This can be done using a variety of techniques, such as k-fold cross-validation or Akaike Information Criterion (AIC).
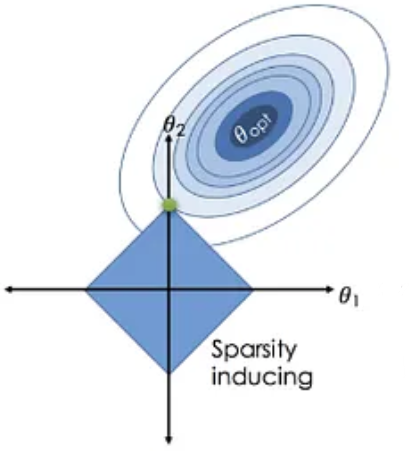
Ridge Regression (reduce overfitting)
Ridge regression, also known as Tikhonov regularization or L2 regularization, adds the squared sum of the coefficients to the cost function. This regularization method is used to reduce overfitting. The regularization term is proportional to the square of the L2 norm of the coefficients: $$\text{Ridge Cost Function} = \frac{1}{2m}\sum_{i=1}^m\left(h_\beta(x^{(i)}) - y^{(i)}\right)^2 + \alpha \sum_{i=1}^n \beta_i^2$$ where:- \(m\) is the number of training examples.
- \(h_\beta(x^{(i)})\) is the predicted value for the \(i-\)th example.
- \(y^{(i)}\) is the actual output for the \(i-\)th example.
- \(\beta_i\) is the coefficient associated with the \(i-\)th feature.
Ridge optimization:
The goal is to find the value of \(\beta\) that minmize the Ridge cost function. The optimization problem can be stated as: $$\underset{\beta}{min} \left(\frac{1}{2m}\sum_{i=1}^m\left(h_\theta(x^{(i)}) - y^{(i)}\right)^2 +\alpha \sum_{i=1}^n \beta_i^2\right)$$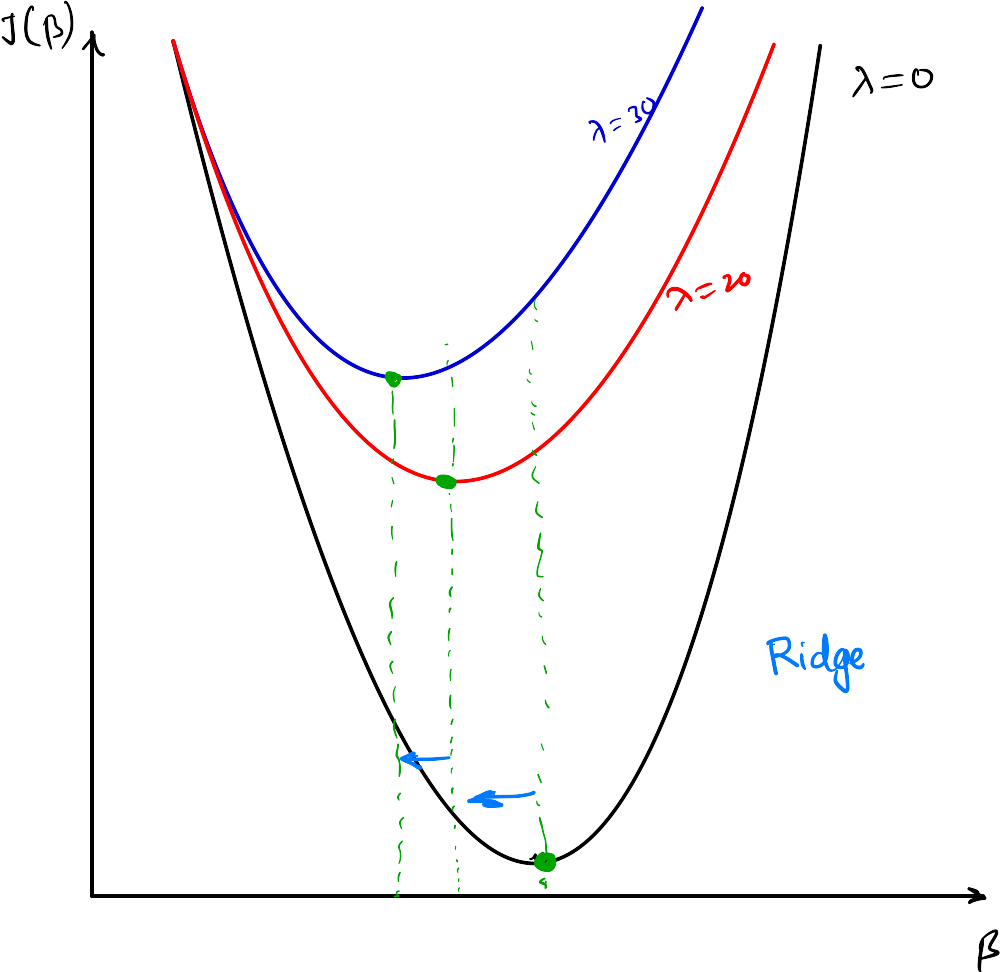
Let's illustrate with an example:
- Suppose our linear regression model without Lasso regularization is: $$h_\theta(x) = \theta_0 +\theta_1 x_1 +\theta_2 x_2+\theta_3 x_3 = 0.34+ 0.48 x_1 + 0.52 x_2 + 0.24 x_3$$
- Now, when we apply Lasso regularization, it can reduce the coefficients, leading to a simpler model: $$h_\theta(x) = 0.34+ 0.32 x_1 + 0.40 x_2 + 0.12 x_3$$
- This means Lasso automatically diminishes the reliance on certain features, in this case, reducing the dependence on the last feature (\(x_3\)) which was already deemed insignificant. The regularization process aids in feature selection, promoting a more robust and interpretable model.
In Scikit-learn, Ridge regression is implemented in the `Ridge` class.
Lasso Regression (feature selection)
Lasso regression, or L1 regularization, adds the sum of the absolute values of the coefficients to the cost function. The regularization term is proportional to the L1 norm of the coefficients: $$\text{Lasso Cost Function} = \frac{1}{2m}\sum_{i=1}^m\left(h_\theta(x^{(i)}) - y^{(i)}\right)^2+ \alpha \sum_{i=1}^n |\beta_i|.$$ Similar to Ridge regression, is the regularization strength. Lasso regression has the property of producing sparse models by setting some coefficients to exact zero. What it means is that the features that are not that important will automatically get deleted and features that are very very important will be considered.Lasso Optimization
The goal is to find the value of \(\beta\) that minmize the Lasso cost function. The optimization problem can be stated as: $$\underset{\beta}{min} \left(\frac{1}{2m}\sum_{i=1}^m\left(h_\theta(x^{(i)}) - y^{(i)}\right)^2 +\alpha \sum_{i=1}^n |\beta_i|\right)$$Example:
When you apply the Lasso method to the linear regression model: $$h_\theta(x) = \theta_0 +\theta_1 x_1 +\theta_2 x_2+\theta_3 x_3 = 0.34+ 0.48 x_1 + 0.52 x_2 + 0.24 x_3$$ Lasso introduces a penalty term to the cost function that contains the absolute values of the coefficients \(\propto \alpha \sum_{i=1}^n |\beta_i|\), where \(\alpha\) is the regularization strength. When using Lasso, it tends to shrink the coefficients towards zero, and it may even set some coefficients exactly to zero. The process of setting Some coefficients to zero is what makes Lasso particulalry useful for feature selection.In simpler terms, Lasso may lead to a model with fewer features by reducing the impact of less important features, possibly making the equation look like:
$$h_\theta(x)= 0.34+ 0.32 x_1 + 0.40 x_2 + 0.12 x_3$$ Notice how some coefficients have been reduced, and it might indicate that the Lasso method has identified and downplayed less influential features, making the model more parsimonious and potentially improving its generalization to new data.Difference between the Ridge and Lasso
- Ridge: Ridge might shrink the coefficients, but it won't set them exactly to zero. It will encourage smaller values fo \(\theta_i\)
- Lasso: Lasso might not only shrink the coefficients but could also set some of them exactly to zero. It tends to prefer sparsity in the model, making it useful for feature selection.
In Scikit-learn, Lasso regression is implemented in the 'Lasso' class.
Usage in scikit-learn:
from sklearn.linear_model import Ridge, Lasso
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Assuming X_train, X_test, y_train, y_test are defined
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Ridge Regression
ridge_reg = Ridge(alpha=1.0) # Adjust alpha as needed
ridge_reg.fit(X_train_scaled, y_train)
ridge_score = ridge_reg.score(X_test_scaled, y_test)
# Lasso Regression
lasso_reg = Lasso(alpha=1.0) # Adjust alpha as needed
lasso_reg.fit(X_train_scaled, y_train)
lasso_score = lasso_reg.score(X_test_scaled, y_test)
Elastic Net
Elastic Net is a regularization technique that combines both L1 (Lasso) and L2 (Ridge) regularization terms in the linear regression cost function. It is particularly useful when dealing with datasets that have a large number of features, and some of these features are correlated. The Elastic Net cost function is a combination of the L1 and L2 regularization terms: $$\text{Elastic Net Cost Function} = \frac{1}{2m}\sum_{i=1}^m\left(h_\beta(x^{(i)}) - y^{(i)}\right)^2 + \alpha \left(\rho \sum_{i=1}^n |\beta_i| +\frac{1-\rho}{2} \sum_{i=1}^n \beta_i^2 \right)$$ where:- Least Squares Cost Function is the standard least squares cost function, which measures the difference between predicted and actual values.
- is the total regularization strength, controlling the overall amount of regularization applied.
- is the mixing parameter that determines the balance between the L1 and L2 regularization. It basically control the trade-off betwee the L1 and L2 regularization.
When:
- \(\rho= 0 \Rightarrow\) Elastic Net is equivalent to Ridge (L2 regularization),
- \(\rho= 1 \Rightarrow\) it is equivalent to Lasso (L1 regularization only).
In mathematical terms, if \(X\) is the feature matrix, \(\beta\) is the vector of coefficients, and \(y\) is the target variables, the Elastic Net cost function can be written as:
$$J(\beta) = \frac{1}{2m} \sum_{i=1}^m \left(y_i - X_i \beta\right)^2 +\alpha \left(\rho \sum_{i=1}^n |\beta_i| +\frac{1-\rho}{2}\sum_{i=1}^n \beta_i^2\right)$$ where- \(m\) = is the number of samples
- \(n\) is the number of features
- \(y_i\) is the target values
- \(X_i\) is the featur vectors
When to Use Elastic Net
- Use Elastic Net when you suspect that there is multicollinearity among your features and you also want the benefit of feature selection.
- It is a more flexible regularization method as it allows you to tune the balance between L1 and L2 penalties.
Example project: Algerian forest fire data analysis
In this project, we have considered the dataset on the ALgerian Forest Fires, which can be obtained from the: website.About the dataset:
The dataset includes 244 instances that regroup a data of two regions of ALgeria, namely the Bejaia region located in the norteast of Algeria and the Sidi Bel-abbes region located in the northwest of Algeria. 122 instances for each region. The period from June 2012 to Septermber 2012. The datset includes attributes and 1 output attribute (class). The 244 instances have been classified into fire (138 classes) and not fire (106 classes) classes.Github repository containg the code:
You can also find the Jupyter notebook from my GitHub repository.- Let's first start with importing the libraries and then the dataset:
I have kept the data file in same directory where the Jupyter notebook is present. This dataset contains two section of data on the basis of the two regions: 'Bejaia region' and 'Sidi Bel-abbes region'. We have created a combined dataset with a column added for the two regions with number 0 for first one and 1 for second region.import pandas as pd import matplotlib.pyplot as plt import numpy as np import seaborn as sns %matplotlib inline df = pd.read_csv('Algerian_forest_fires_dataset_UPDATE.csv', header=1)
After doing the data engineering we will have our final data frame (for more details on it, you can look at Jupyter notebook).# Extract data for the Bejaia region bejaia_data = df.iloc[bejaia_header_row :sidi_bel_abbes_header_row].copy() # Extract data for the Sidi-Bel Abbes region sidi_bel_abbes_data = df.iloc[sidi_bel_abbes_header_row:].copy() # Add a new column 'Region' with values 0 for the Bejaia region and 1 for the Sidi-Bel Abbes region bejaia_data['Region'] = 0 sidi_bel_abbes_data['Region'] = 1 # Concatenate the two DataFrames back together final_df = pd.concat([bejaia_data, sidi_bel_abbes_data]) # Reset the index of the final DataFrame final_df.reset_index(drop=True, inplace=True) - Extrapolatory data analysis:
- Histogram plots:
## Density plot for all features df_copy.hist(bins=50, figsize=(20,15), grid=False) plt.show()
- Pie chart for the classes:
## PErcentage for category percentage = df_copy['Classes'].value_counts(normalize=True)*100 # Pie chart for the category classlabels = ["Fire", "Not Fire"] plt.figure(figsize=(12,7)) # Corrected the function name to plt.figure plt.pie(percentage, labels=classlabels, autopct='%1.1f%%') plt.title("Pie chart of classes") plt.show()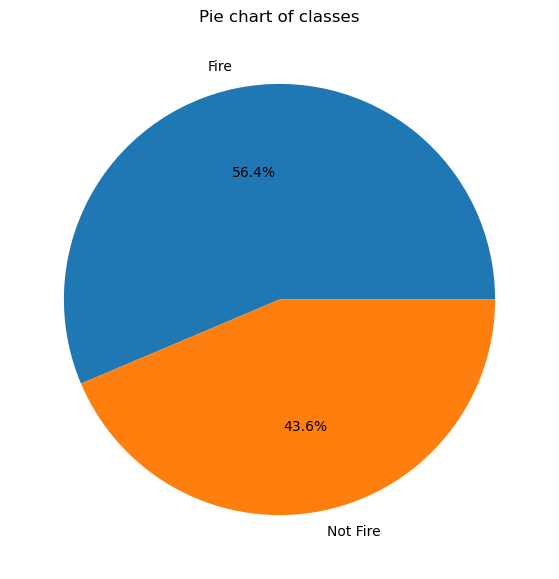
- Correlation plots:
# Calculate the correlation matrix correlation_matrix = df_copy.corr() # Create a mask to hide the upper triangle of the correlation matrix mask = np.triu(np.ones_like(correlation_matrix, dtype=bool), k=1) # Plotting the heatmap with the upper triangle masked plt.figure(figsize=(12, 10)) sns.heatmap(correlation_matrix, annot=True, cmap='Greens', fmt=".2f", linewidths=.5, mask=mask) plt.title('Trimmed Correlation Matrix Heatmap') plt.show()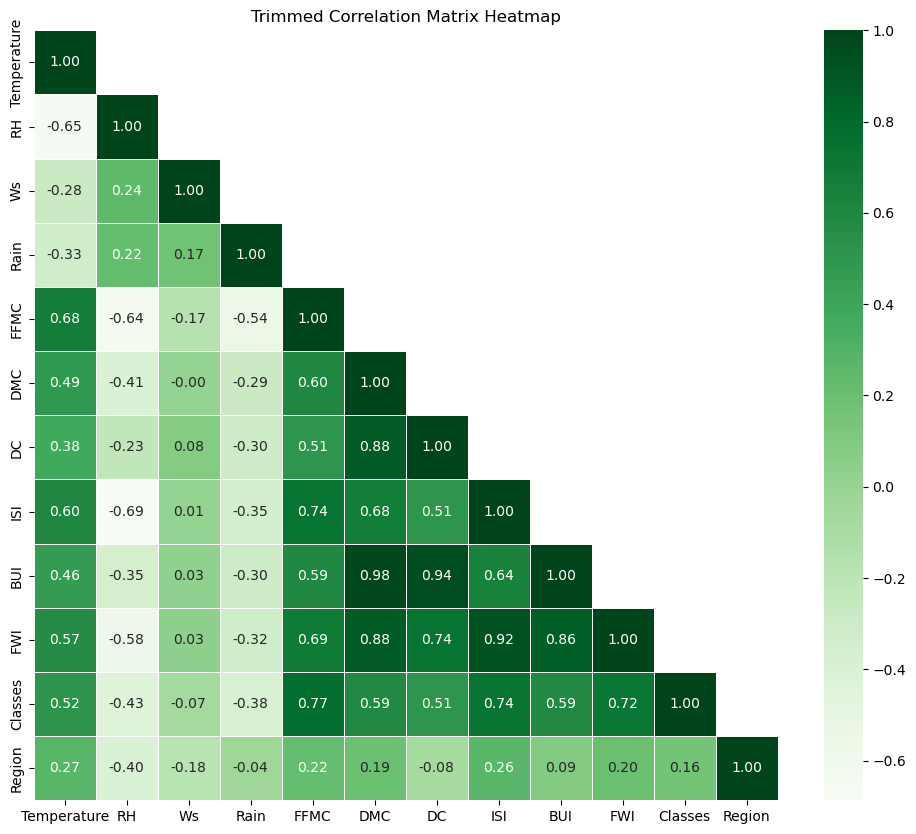
- Checking the outliers in FWI column
## Box plot to see the outliers sns.boxplot(df_copy['FWI'], color='y') plt.show()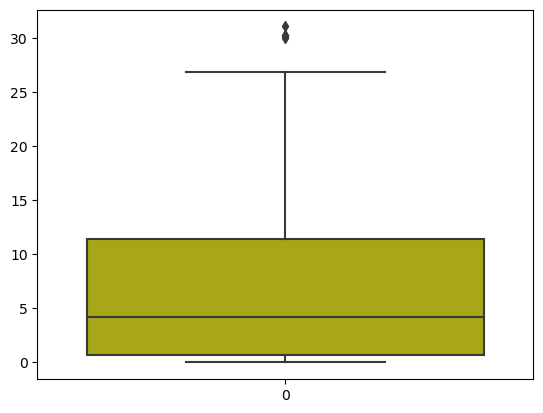
- Monthly fire analysis:
dftemp = final_df.loc[final_df['Region'] == 1] # here for second region it should be 0. plt.subplots(figsize=(13,6)) sns.countplot(x='month', hue='Classes', data=final_df) plt.ylabel('Number of FIres', weight='bold') plt.xlabel('Months', weight='bold') plt.title("Fire analysis of Sidi-Bel Abbes region", weight='bold') plt.show()
The combined plot for the two regions can be seen here:
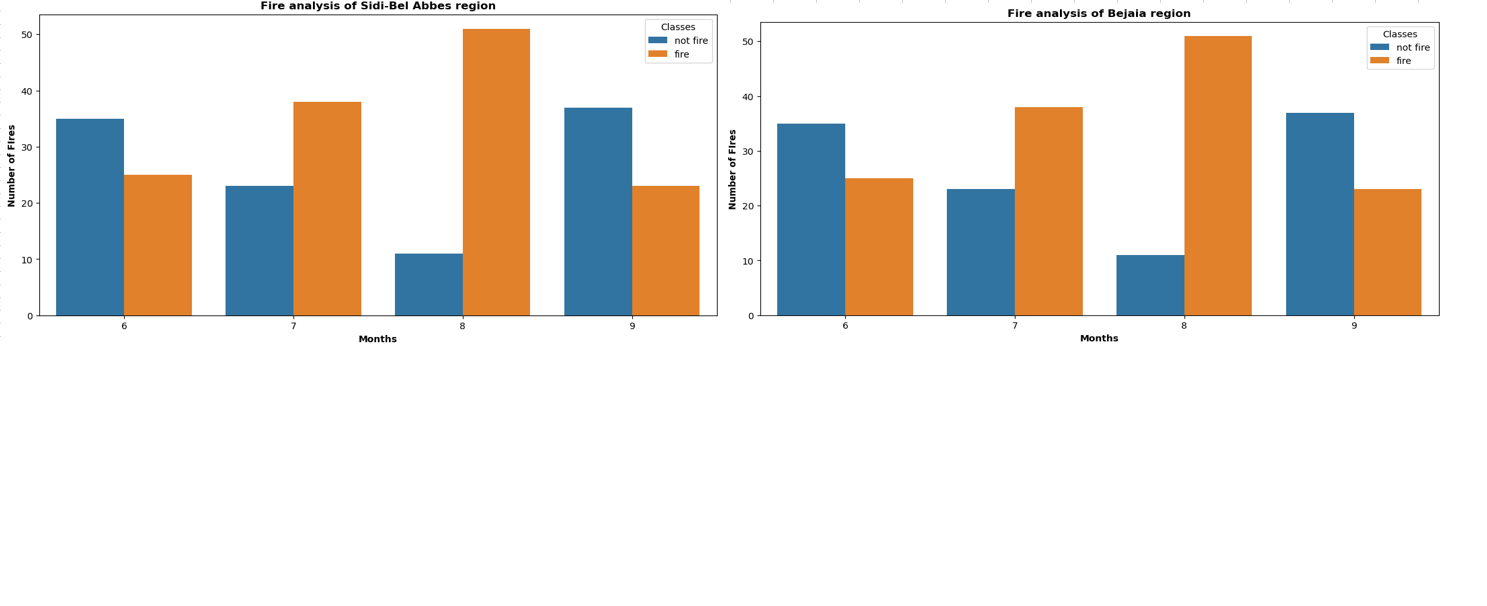
- Histogram plots:
- Ridge lasso analysis:
In this part, we will work on ridge lasso analysis part. The original code can be found at my github repository
- Feature scaling or standardization:
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_train_scaled =scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test) plt.subplots(figsize=(15,5)) plt.subplot(1,2,1) sns.boxplot(data = X_train) plt.title("X_train before scaling") plt.subplot(1,2,2) sns.boxplot(data = X_train_scaled) plt.title("X_train After scaling") plt.show()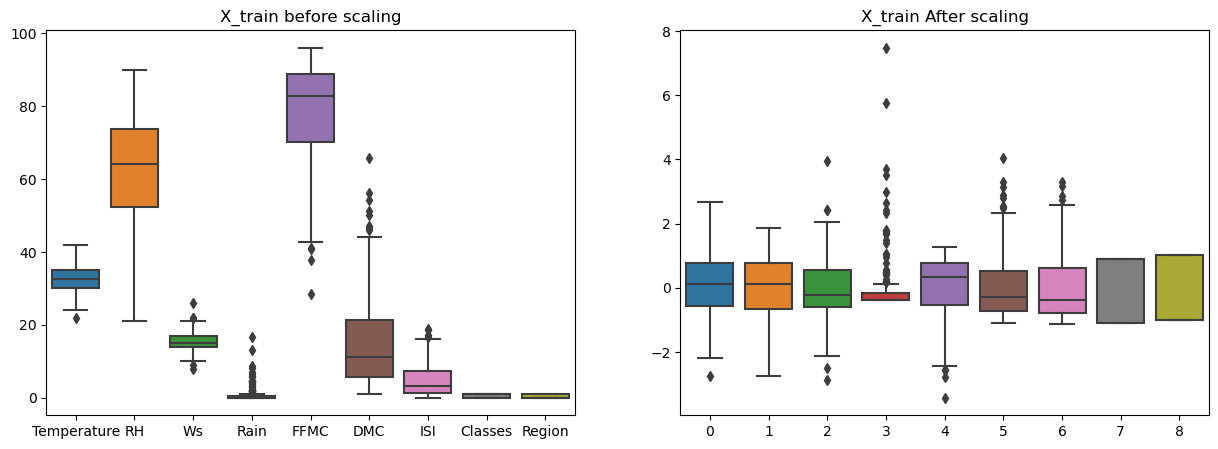
- Linear-regression method:
Here we will start with linear regression method.
Output of this is:from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error linreg = LinearRegression() linreg.fit(X_train_scaled, y_train) y_pred =linreg.predict(X_test_scaled) mae = mean_absolute_error(y_test, y_pred) mse = mean_squared_error(y_test, y_pred) score = r2_score(y_test, y_pred) print(f'Mean absolute error = {mae}') print(f'Mean squared error = {mse}') print(f'R-squared value = {score}')Mean absolute error = 0.5468236465249976 Mean squared error = 0.6742766873791581 R-squared value = 0.9847657384266951 - Lasso Regression:
The output is:from sklearn.linear_model import Lasso from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error lasso = Lasso() lasso.fit(X_train_scaled, y_train) y_pred =lasso.predict(X_test_scaled) mae = mean_absolute_error(y_test, y_pred) mse = mean_squared_error(y_test, y_pred) score = r2_score(y_test, y_pred) print(f'Mean absolute error = {mae}') print(f'Mean squared error = {mse}') print(f'R-squared value = {score}')Mean absolute error = 1.1331759949144085 Mean squared error = 2.2483458918974746 R-squared value = 0.9492020263112388Lasso Cross validation:
Now we can see the LassoCV the MSE with respect to alphafrom sklearn.linear_model import LassoCV lassocv = LassoCV(cv=5) lassocv.fit(X_train_scaled, y_train) y_pred = lassocv.predict(X_test_scaled)# Plot MSE path plt.figure(figsize=(10, 6)) plt.plot(lassocv.alphas_, lassocv.mse_path_, ':') plt.plot(lassocv.alphas_, lassocv.mse_path_.mean(axis=-1), 'k', label='Average MSE') plt.axvline(lassocv.alpha_, linestyle='--', color='r', label='Selected Alpha') plt.legend() plt.xscale('log') plt.xlabel('Alpha (Regularization Strength)') plt.ylabel('Mean Squared Error (MSE)') plt.title('LassoCV Mean Squared Error Path') plt.show()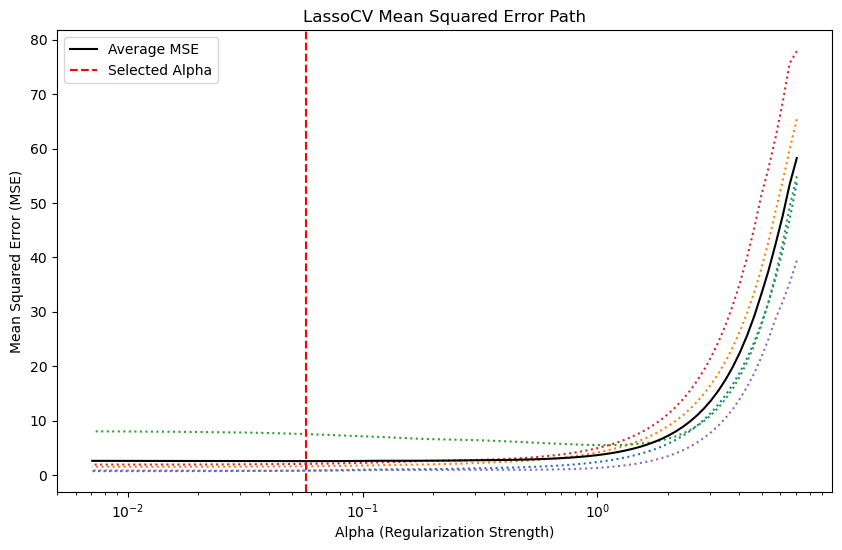
- Ridge regression model:
The output of this is:from sklearn.linear_model import Ridge from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error ridge = Ridge() ridge.fit(X_train_scaled, y_train) y_pred =ridge.predict(X_test_scaled) mae = mean_absolute_error(y_test, y_pred) mse = mean_squared_error(y_test, y_pred) score = r2_score(y_test, y_pred) print(f'Mean absolute error = {mae}') print(f'Mean squared error = {mse}') print(f'R-squared value = {score}')Mean absolute error = 0.5642305340105693 Mean squared error = 0.6949198918152067 R-squared value = 0.9842993364555513Ridge cross validation:
The output of this:from sklearn.linear_model import RidgeCV ridgecv = RidgeCV(cv=5) ridgecv.fit(X_train_scaled, y_train) y_pred = ridgecv.predict(X_test_scaled) mae = mean_absolute_error(y_test, y_pred) score = r2_score(y_test, y_pred) print(f"Mean absolute error={mae}") print(f"R-squared value = {score}")Mean absolute error=0.5642305340105693 R-squared value = 0.9842993364555513 - Elastic Net regression:
The output of this is:from sklearn.linear_model import ElasticNet from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error elastic = ElasticNet() elastic.fit(X_train_scaled, y_train) y_pred =elastic.predict(X_test_scaled) mae = mean_absolute_error(y_test, y_pred) mse = mean_squared_error(y_test, y_pred) score = r2_score(y_test, y_pred) print(f'Mean absolute error = {mae}') print(f'Mean squared error = {mse}') print(f'R-squared value = {score}')Mean absolute error = 1.8822353634896 Mean squared error = 5.517251101025224 R-squared value = 0.8753460589519703Elasticnet cross validation:
The output is:from sklearn.linear_model import ElasticNetCV from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error elasticcv = ElasticNetCV() elasticcv.fit(X_train_scaled, y_train) y_pred =elasticcv.predict(X_test_scaled) mae = mean_absolute_error(y_test, y_pred) mse = mean_squared_error(y_test, y_pred) score = r2_score(y_test, y_pred) print(f'Mean absolute error = {mae}') print(f'Mean squared error = {mse}') print(f'R-squared value = {score}')Mean absolute error = 0.6575946731430904 Mean squared error = 0.8222830416276272 R-squared value = 0.9814217587854941Variation of Mean squared error with respect to various values of alphas can be seen here:# Plot MSE path plt.figure(figsize=(10, 6)) plt.plot(lassocv.alphas_, lassocv.mse_path_, ':') plt.plot(elasticcv.alphas_, elasticcv.mse_path_.mean(axis=-1), 'k', label='Average MSE') plt.axvline(lassocv.alpha_, linestyle='--', color='r', label='Selected Alpha') plt.legend() plt.xscale('log') plt.xlabel('Alpha (Regularization Strength)') plt.ylabel('Mean Squared Error (MSE)') plt.title('Elasticnet Cross validation Mean Squared Error Path') plt.show()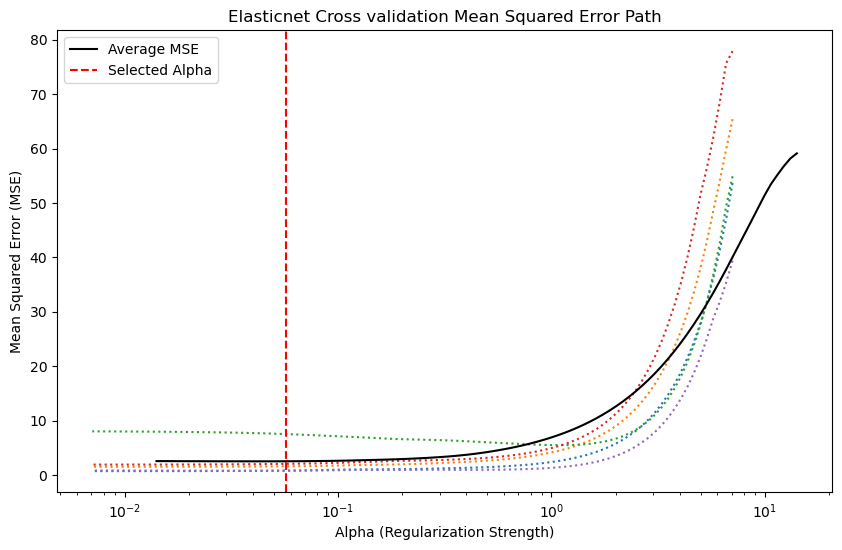
- Feature scaling or standardization:
References
- My github Repositories on Machine learning.
- A Brief description with all individual concpet can be found in my Jupyter notebook (Best reference for theory and visualization).
- Lasso & Ridge Regression in 200 words.
- A Visual Introduction To Linear regression (Good reference).
- Book on Regression model: Regression and Other Stories
- Book on Statistics: The Elements of Statistical Learning
- A nice mathematical description is available at youtube video.
- Lasso model selection and cross validation
Some other interesting things to know:
- Visit my website on For Data, Big Data, Data-modeling, Datawarehouse, SQL, cloud-compute.
- Visit my website on Data engineering